The era of contextual RAG is here - to stay?
Given the pace at which we are progressing, we are not far from AI training itself to come up with its own better version. This may sound a bit sci-fi. But so did it when I was told that robot vacuum cleaners can charge themselves by docking themselves to the base! But robot vacuum cleaners are in many households!
Visual Explanation
If you are like me and would like an audio-visual explanation of the idea (with a pit stop on TF-IDF and BM25), then please check this video:
The LLM era
We already live in a world where we ask an LLM like ChatGPT .. for every single question we have about our day-to-day activities. For example, just last week I asked an LLM to plan a 5-day trip to Dubai. I even throw the list of items in my fridge to come up with innovative dishes I can cook.
Drawbacks of LLMs
Even with such sophistication, LLMs have a couple of drawbacks.
- They lack specialized knowledge about a domain. For example, if you are building a bot to help your technical support team, it may not know anything about the repeated queries your support team gets. Additionally, it doesn’t know the error codes and technical terms of your in-house system.
- LLMs tend to hallucinate a lot. Hallucinations are imaginary answers that LLMs cook up whenever they lack knowledge about certain user queries.
The RAG era
To address the limitations of LLMs, Retrieval Augmented Generation(RAG) systems were proposed. They enable LLMs to access in-house data thereby augmenting their knowledge about any specialized domain.
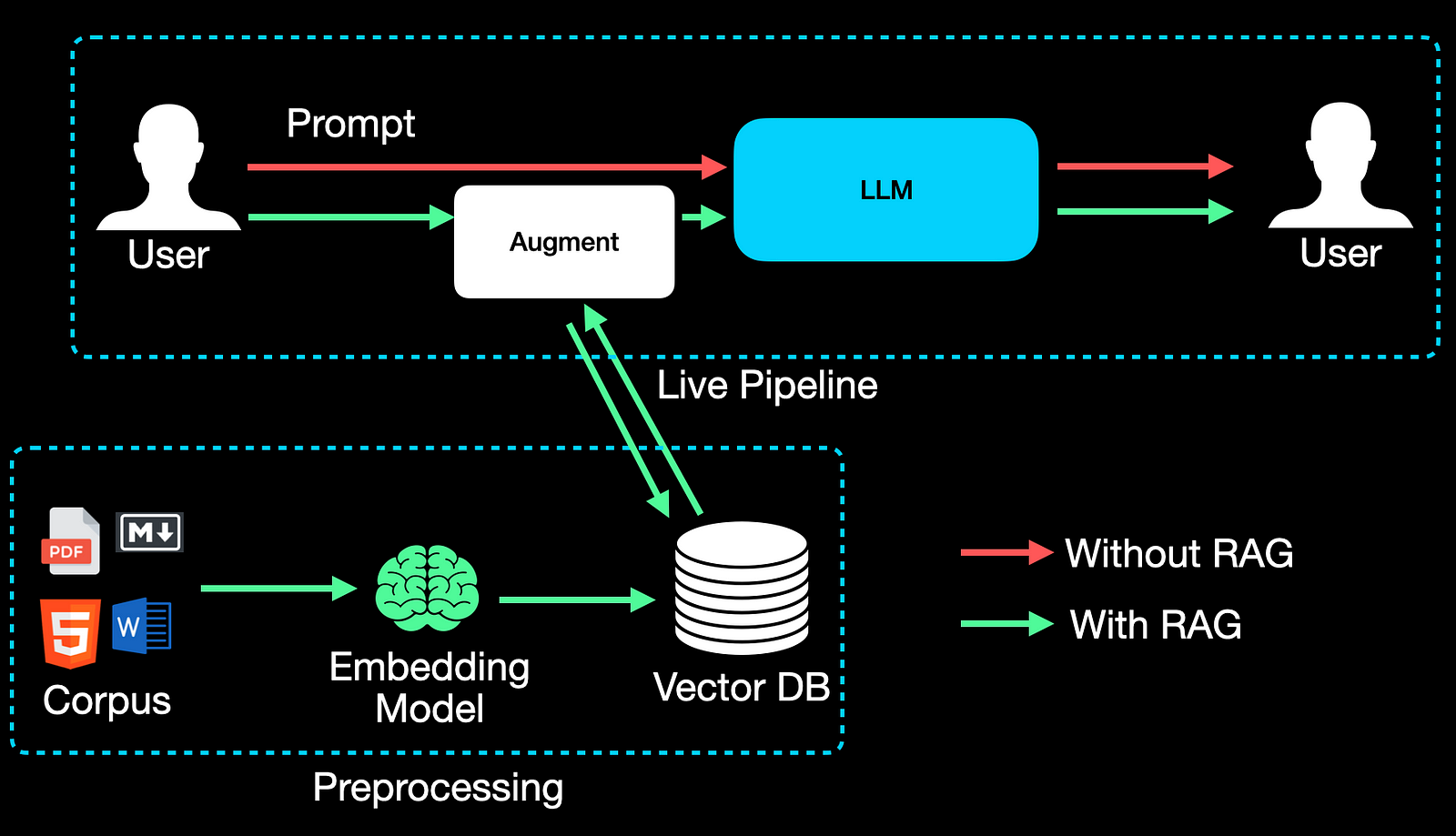
Above are the main building blocks of a naive RAG system. The preprocessing pipeline is run offline to produce embedding vectors that get stored in a Vector DB.
Drawbacks of RAG
At the heart of a RAG preprocessing pipeline are embedding models. They naturally abstract information in their embedding space. In a dataset about pets, it's quite likely that a data point about horses could be prevalent in the middle of the data about dogs.
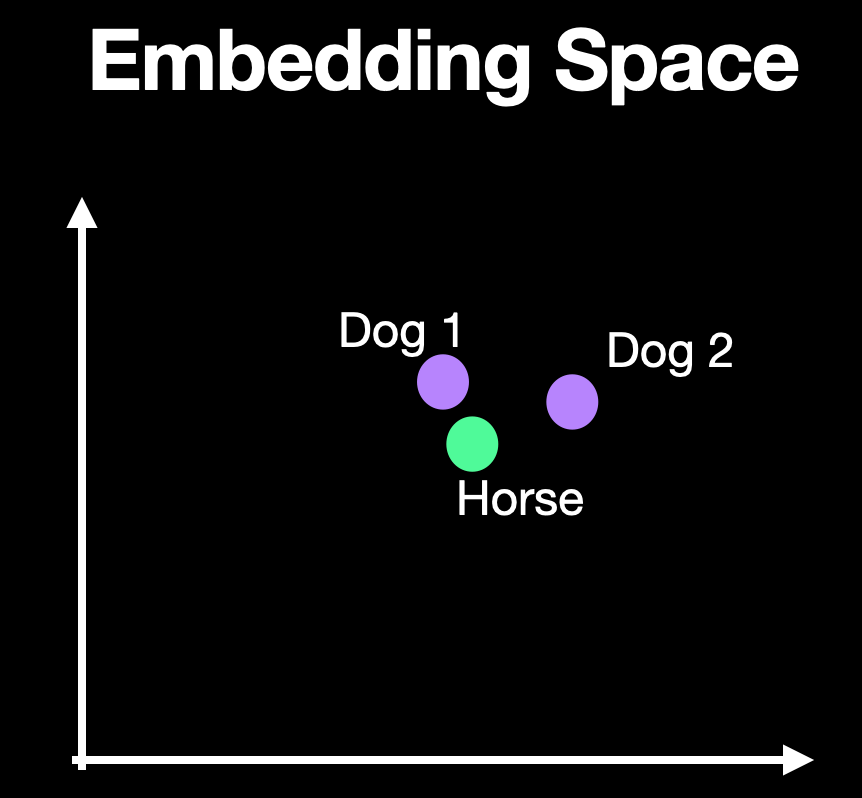
Whenever a user queries about dogs, the data point about horse also tags along and gets returned in the query. This is not acceptable and could lead to confusing and sometimes even wrong responses to the user.
From RAG to Hybrid RAG
The problem with embedding models can be tackled with Hybrid RAG which is a type of advanced RAG. Classic ideas from information retrieval come to the rescue. Information retrieval systems fetch data that are an “exact match”. The schematic of a hybrid RAG system now becomes somewhat like below:
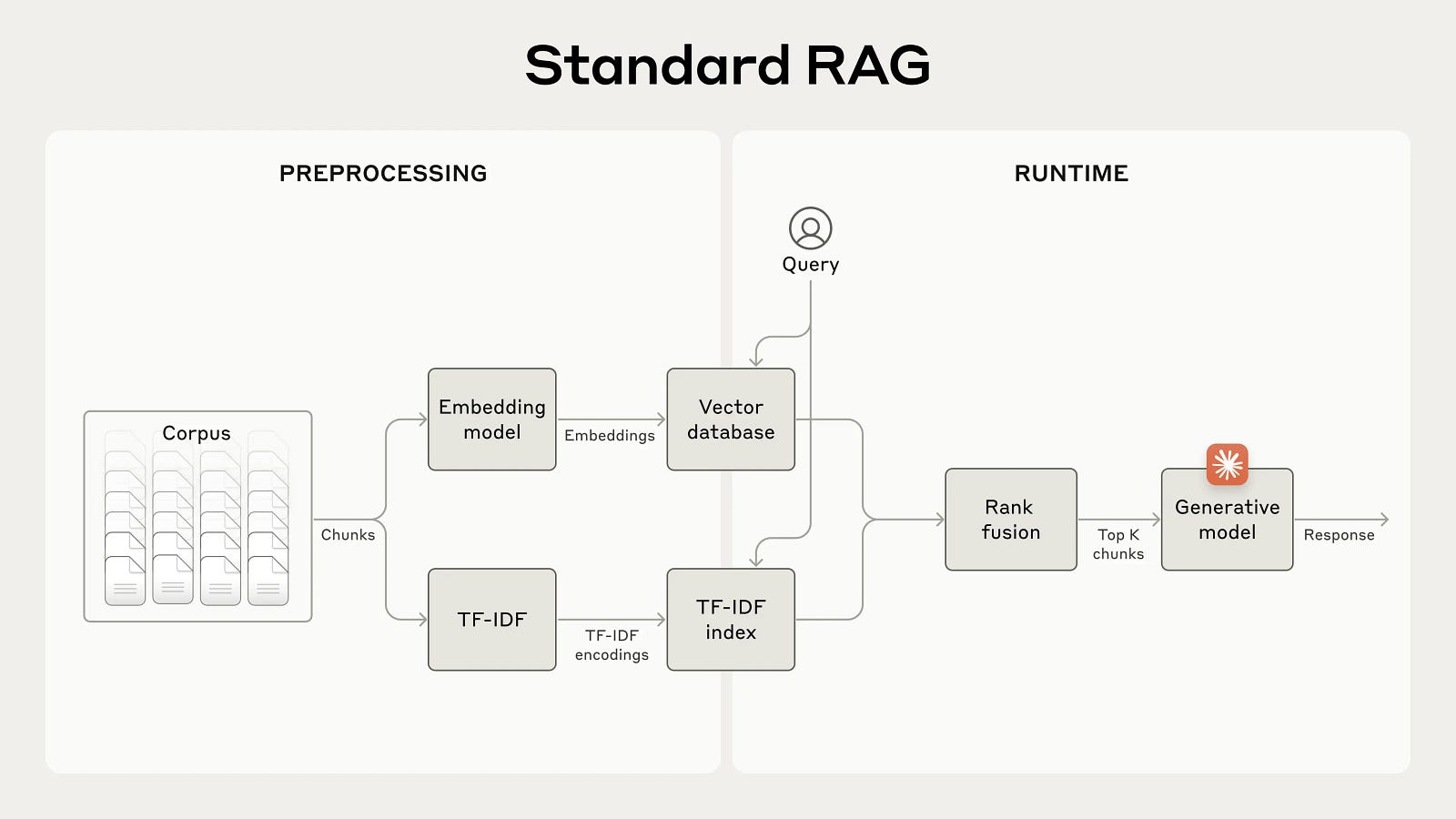
The preprocessing branch now has two branches — one using the embedding model and the other using classic information retrieval algorithms. More specifically, they use TF-IDF and/or BM25.
A tour of TF-IDF and Best Match 25(BM25)
If you are unfamiliar with TF-IDF and BM25, please refer to my previous article, which dives deeper into them with illustrative examples.
Hybrid RAG and context
Though hybrid RAG addresses one problem with RAG, it still doesn’t overcome the problem with context. For example, let the names of two dogs be Jack and Snowy in the pets dataset we have in-house. Let's say we have two document chunks like this:
- Jack is well-trained in many commands. He is very obedient and learns new commands very fast.
- He is still being potty trained.
Now, let the query from the user be “Jack”. The second chunk above is quite ambiguous. We may be tempted to think that it refers to Jack. But what if it actually refers to Snowy?! So this chunk lacks context.
The solution to this lies with contextual retrieval.
Contextual Retrieval to the Rescue
What if we now have the context, “Snowy is just an 8 weeks old puppy”. The second document chunk brings a lot of context and now refers to Snowy rather than Jack. This is what contextual retrieval is all about.
The solution from Anthropic is to leave the context generation to the LLM itself. They prompt an LLM (Claude 3 Haiku) to generate a context for the given query. They use the below prompt for this purpose:

In doing so, the LLM provides the context. We then happily append the provided context to the user query. The updated schematic is shown in the figure below:
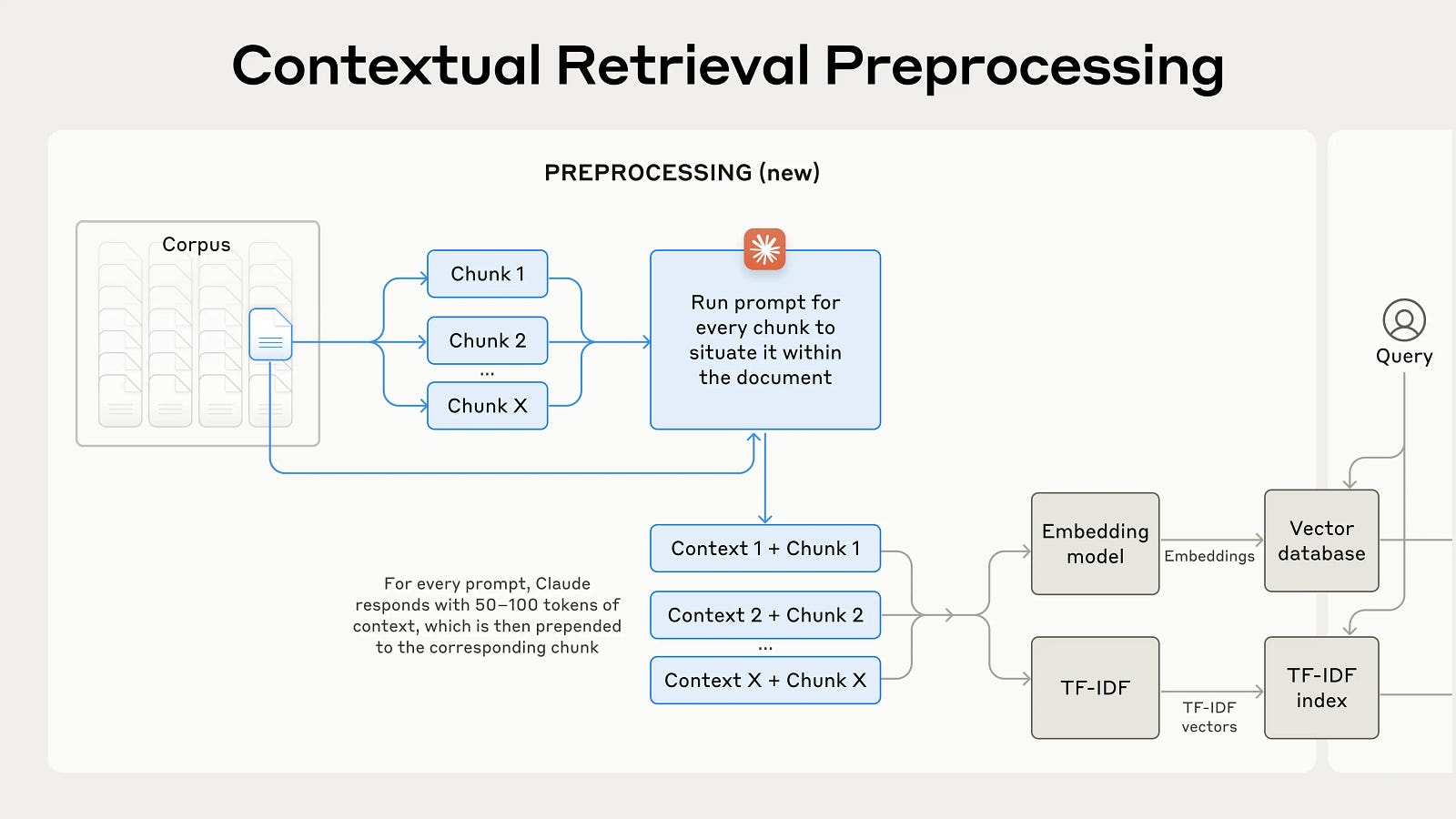
So we not only pass the chunks but also the Claude 3 Haihu generated context. And that is all there is to contextual retrieval. The idea is fairly simple but powerful as depicted by their results.
Performance Comparison
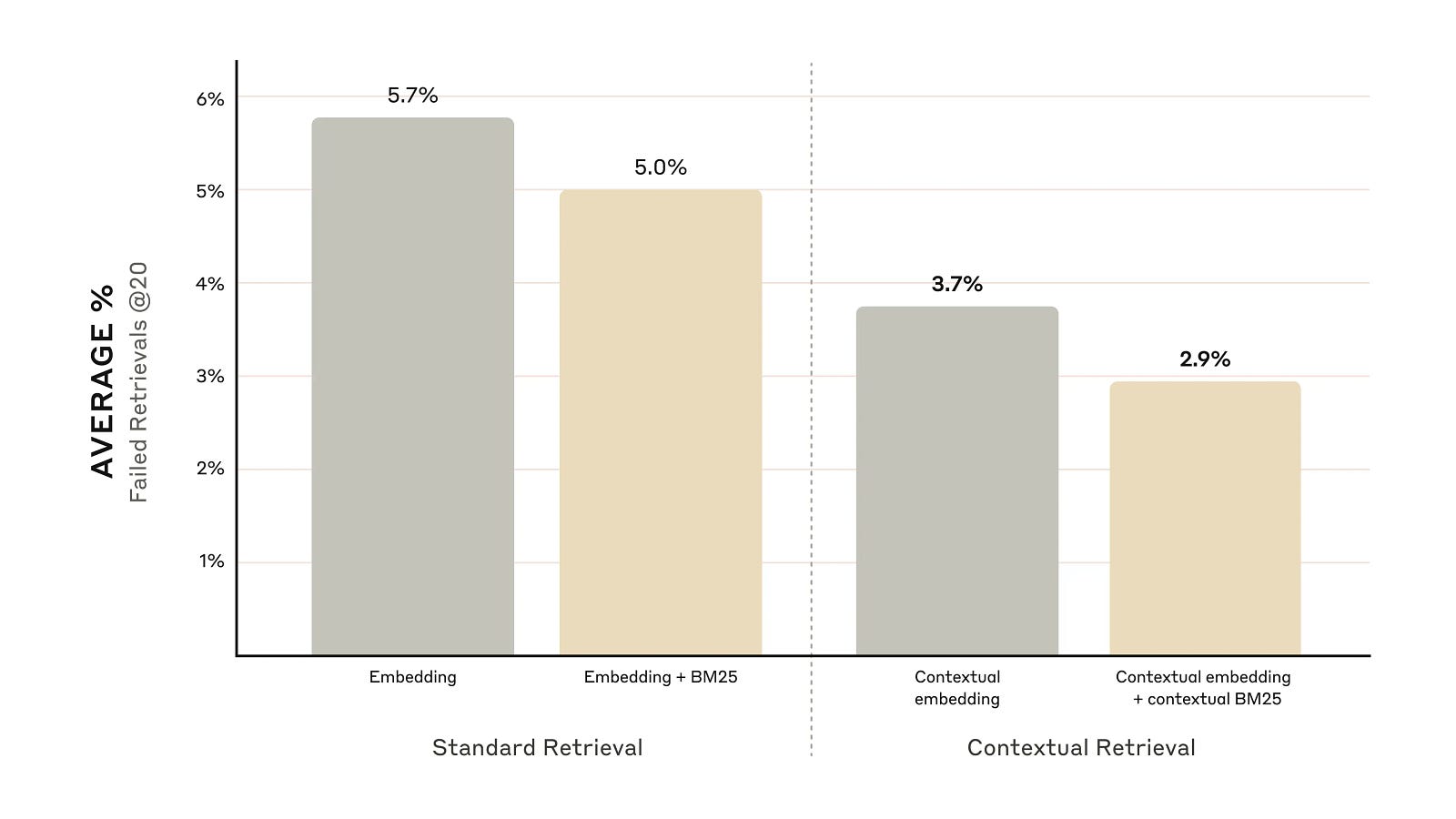
As seen from the plot from their blog, combining context with embeddings and BM25 leads to a significant decrease in failed retrievals. The failure rate drops from 5% to 2.9%.
Conclusion
Contextual retrieval is a novelty in an already novel bleeding-edge RAG technology. As seen from the results, it seems to improve the performance of RAG pipelines. It's up to us to implement them in our RAG pipeline and make the most of this. Let’s not forget that we will have twice the number of calls to the LLM as we now get the context from the LLM and pass it back to the generative model which is also an LLM!