TF-IDF and BM25 for RAG— a complete guide

TF-IDF and BM25 are commonly used techniques in information retrieval. while TF stands for Term-Frequency, IDF stands for Inverse Document Frequency and BM stands for Best Match. The number 25 after BM indicates the number of iterations of the BM algorithm. It took 25 iterations before being widely adopted and accepted, though we have BM25+ and other variations.
Before we dive deep, let us keep at the back of our mind that all these are ranking algorithms used to retrieve information that best “matches” the user’s query.
Example for illustration
Let's understand the concepts with a simple toy corpus example. Let's take a small corpus composed of three documents as shown in the figure below.

Let's assume the user’s query is “dogs”.
TF-IDF
TF is the easiest and one of the earliest approaches to retrieval. It states that we need to count the occurrence of the search term in a given document. As our query is “dogs”, the TF values are:

We compute IDF for the entire corpus and not just a single document. It measures the importance of a term (“dogs” in our case) across the entire corpus. It's the logarithm of the total number of documents in the corpus divided by the number of documents containing the term. So, the IDF score for our example is log(3/2) as “dogs” occur in 2 of the 3 documents.
Calculating TF-IDF simply boils down to multiplying the two terms TF and IDF. So, the results show that document 2(d2) will be retrieved.

Including Normalization…
There is a small problem however with our TF-IDF calculation. We haven’t considered the length of our document. It matters how long a sentence is and we cannot ignore that. For example, though “dogs” occurs 3 times in the second document (d2), there are 25 words in it. But the first document(d1) only has 5 words. So let's normalize our TF-IDF by simply dividing it with the document length.

Suddenly, our retrieval result return document 1 (d1) instead of document 2(d2) as TF-IDF(“dogs”, d1) > TF-IDF(“dogs”, d2). We can make it more sophisticated by including something called saturation.
Including Saturation…
Saturation is the idea that words should get lesser weightage or value as they occur more and more in a document. Let's consider the second document, “Cats and dogs are pet animals though I prefer dogs. Dogs obey our commands, can be trained easily, and play with us all the time”. What if the document keeps repeating the term, “dogs” over and over again? As the term frequency increases, we will give lesser and lesser weightage to terms as shown in the plot from the paper on BM25.
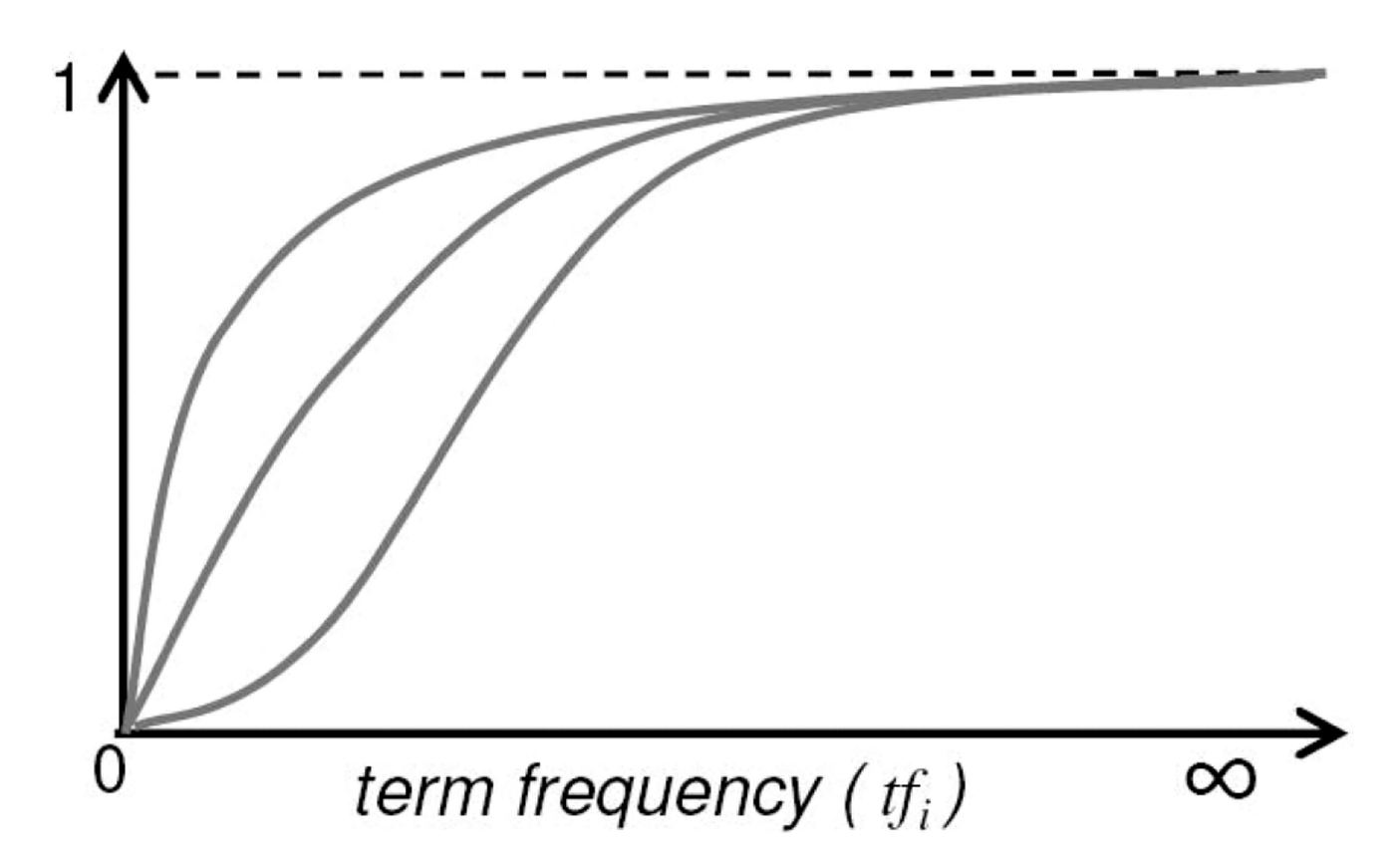
Best Match 25(BM25)
If we incorporate saturation and document length into TF-IDF, we will arrive at the BM algorithms. More specifically, we are interested in the most popular BM25 which incorporates saturation function and document length using this scary-looking formula:

To calculate BM25, we will have to include the average length of the document which is fairly easy for our toy corpus, which is (5 + 25 + 4) / 3 = 11.33.
We have a couple of additional parameters k_1 and b. These are the hyperparameters chosen by us. But typically k_1 is 1 or 2 and b is 0.75.
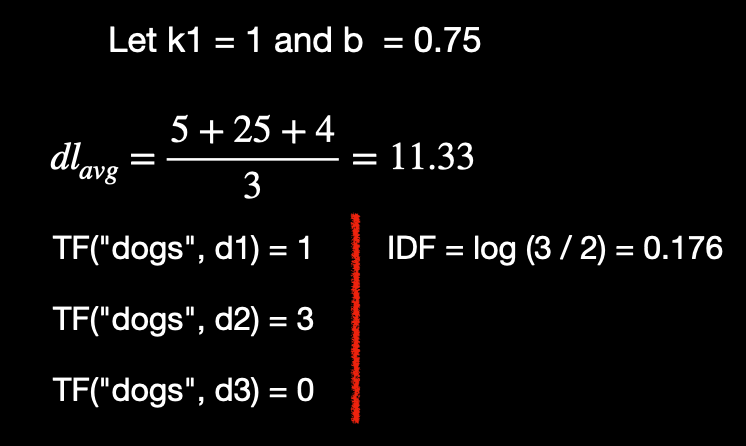
I have done all the math for you and plugged in the above values in the BM25 equation which leads to,

Thats it! We have just calculated the BM25 for the term “dogs” on our toy corpus of 3 sentences.
Implementation
TF-IDF
Let's also quickly see the code in action. We are going to use sklearn for this. To visualize the results, we are going to use Pandas data frames.
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'cats and dogs are pets.',
'cats and dogs are pet animals though I prefer dogs. Dogs obey our commands, can be trained easily and play with us all the time.',
'And this is the third one.',
'Horses are also pets',
]
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(corpus)
vectorizer.get_feature_names_out()
feature_names = vectorizer.get_feature_names_out()
tfidf_df = pd.DataFrame(data=X.toarray(),columns=feature_names)
tfidf_df = pd.DataFrame(data=X.toarray(), columns=feature_names)
print(tfidf_df)
After running the code, we get something like this, which shows the values for each of the terms in the document as a grid as below. We can see that the term “dogs” has a higher value in the first sentence than in the second.
all also and animals are be can cats commands dogs ... play prefer the third this though time trained us with
0 0.000000 0.00000 0.389925 0.000000 0.389925 0.000000 0.000000 0.481635 0.000000 0.481635 ... 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
1 0.200504 0.00000 0.255958 0.200504 0.127979 0.200504 0.200504 0.158079 0.200504 0.474238 ... 0.200504 0.200504 0.158079 0.000000 0.000000 0.200504 0.200504 0.200504 0.200504 0.200504
2 0.000000 0.00000 0.284626 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 ... 0.000000 0.000000 0.351570 0.445922 0.445922 0.000000 0.000000 0.000000 0.000000 0.000000
3 0.000000 0.57458 0.000000 0.000000 0.366747 0.000000 0.000000 0.000000 0.000000 0.000000 ... 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
BM25
For BM25, let's use a library called bm25s. Though there are a handful of libraries for calculating BM25, I found this to be lightweight and sufficient to illustrate our example. We will have to install bm25s using pip:
pip install bm25s
pip install bm25s[full]
pip install PyStemmer
And then the code for calculation,
import bm25s
Create your corpus here
corpus = [
'cats and dogs are pets.',
'cats and dogs are pet animals though I prefer dogs. Dogs obey our commands, can be trained easily and play with us all the time.',
'And this is the third one.',
'Horses are also pets',
]
Tokenize the corpus and only keep the ids (faster and saves memory)
corpus_tokens = bm25s.tokenize(corpus, stopwords="en")
Create the BM25 model and index the corpus
retriever = bm25s.BM25()
retriever.index(corpus_tokens)
Query the corpus
query = "dogs"
query_tokens = bm25s.tokenize(query)
Get top-k results as a tuple of (doc ids, scores). Both are arrays of shape (n_queries, k)
results, scores = retriever.retrieve(query_tokens, corpus=corpus, k=2)
Let's print the results and scores to see how they look:
print(results)
[['cats and dogs are pets.'
'cats and dogs are pet animals though I prefer dogs. Dogs obey our commands, can be trained easily and play with us all the time.']]
print(scores)
[[0.3659254 0.32038802]]
As expected, it has retrieved the two documents d1 and d2. The first document has a higher score of 0.36 compared to the second with a score of 0.32, which is expected.
Conclusion
The BM25 algorithm is becoming the go-to algorithm for building advanced RAG pipelines. More specifically, for hybrid RAG which involves both retrieval and embeddings. It only proves that classic ideas cannot be ditched even in the modern-day era of AI.
Please stay tuned for my next article on the bleeding edge “contextual retrieval” from Anthropic which also uses BM25. It was released only last week 😃