Self-Adaptive Dynamic LLMs are here!

Adapting to the environment is an extremely important trait for survival. An octopus is a good example of an adaptive being. It changes colors and shapes to mold itself to the environment. LLMs on the other hand are quite static and rigid, unable to mould to the environment (think input prompts).
Non-members can read for free here. Why not subscribe there to get articles like this straight to your inbox?
Visual Explanation
If you are like me and would like to watch a video explaining the paper, here it is:
What are self-adaptive LLMs?
Self-adaptive LLMs can be standalone or a group of LLMs that can evaluate and modify their behavior in response to changes to their operating environment without any external intervention.
Now, that's a mouthful. So let's dive in.
The LLMs we are seeing today are juggling multiple hats. While one user is asking about the weather, another is asking it to diagnose a disease by providing the symptoms they are facing. In the real world, there are NO humans who are experts in more than 2 or 3 fields. To infuse multiple specialties into LLMs we take a macro or micro view of the world.
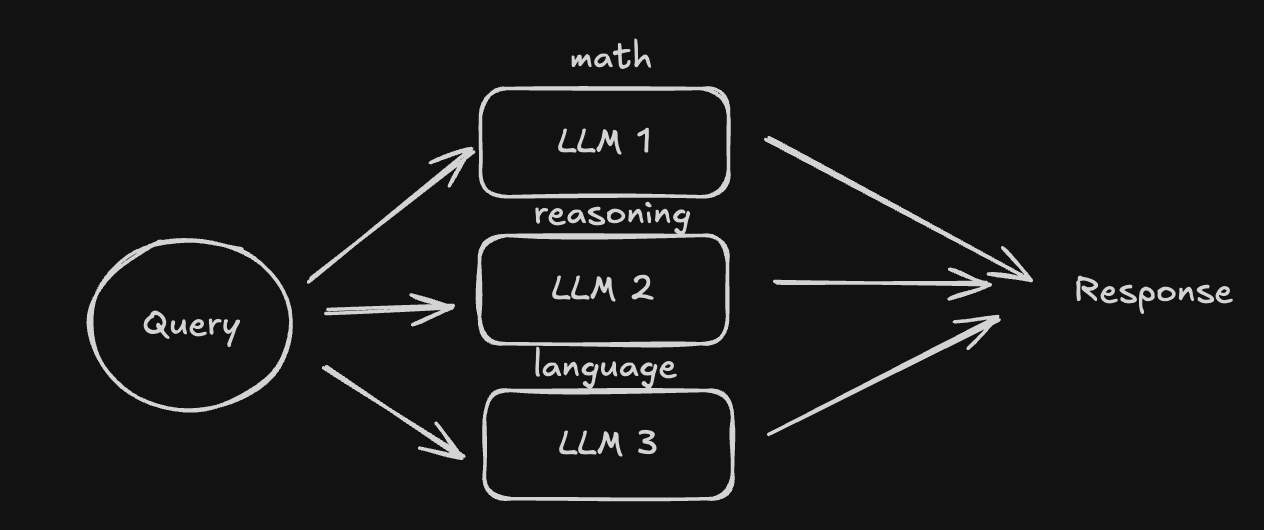
- Macroview. We can use multiple LLMs in the system, each specializing in different tasks. We can route the query to the right LLM based on the user's query. This is equivalent to having an ensemble model in traditional machine learning. The combination of the whole is better than each individual. Though this is a good approach, think of the compute involved in running each of the LLMs. The performance is also limited to how accurate the routing is.
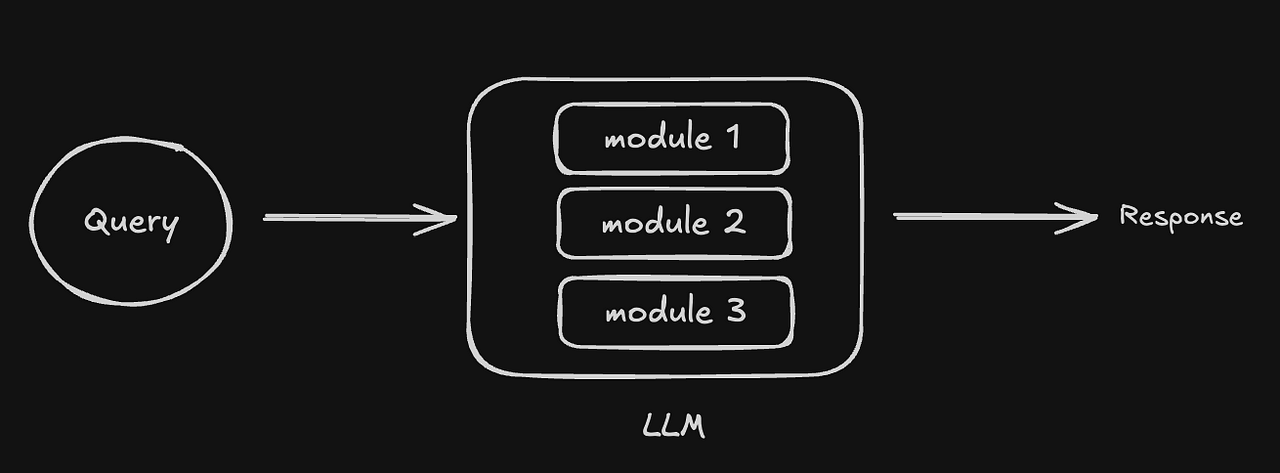
- Microview. We can take a micro view and say that we will use a single LLM but the different modules of the LLM specialize in various tasks. The LLM internally decides which module to use based on the user query. This is what the Mixture of Experts (MoE) models use.
Though the proposed approach is similar to the micro view above, it differs from MoE in that it uses Singular Value Decomposition (SVD) at its heart.
So, what is SVD?
Quick SVD recap
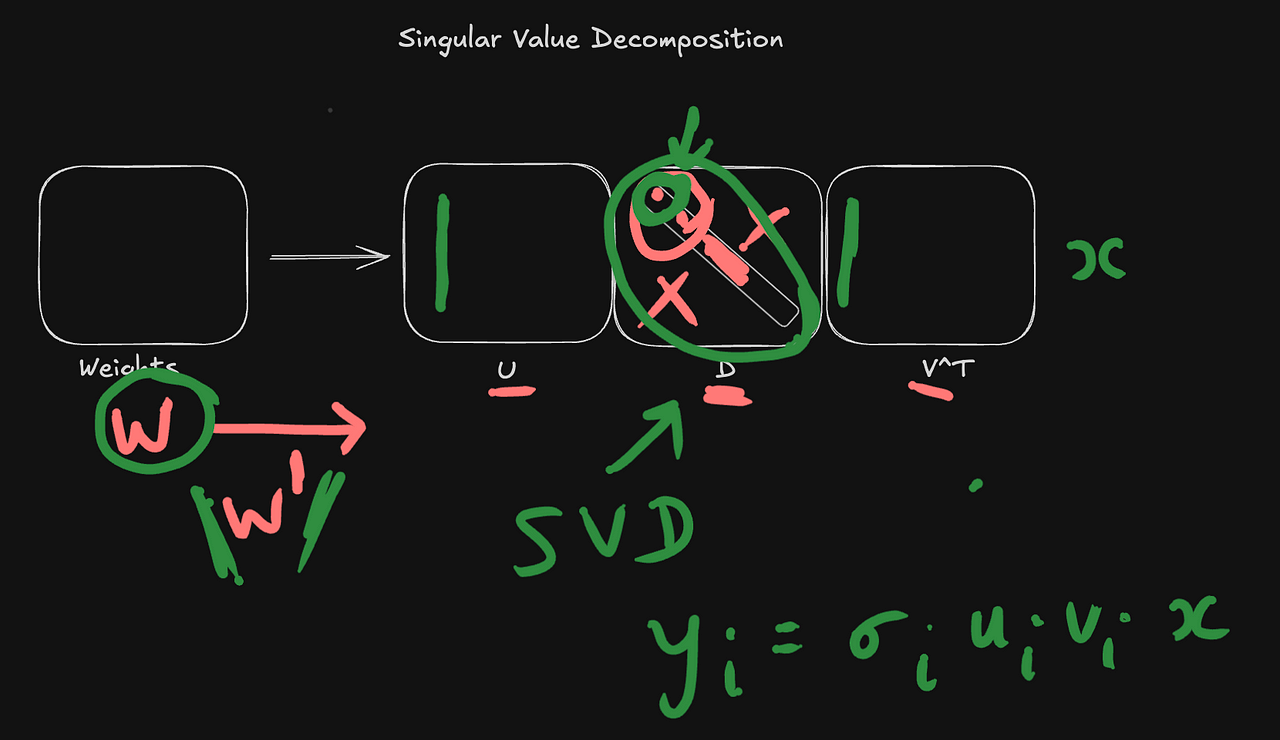
The technical foundation of this system rests on Singular Value Decomposition (SVD), a mathematical technique that breaks down complex matrices into simpler components. The model’s weight matrix is decomposed into three parts, or matrices, which are U, D, and V. Here, D is a diagonal matrix that just has diagonal elements, and the rest of the matrix is zeros.
The beauty of this factorization is that the diagonal matrix D can be used to orchestrate the value of the decomposed matrix. In other words, if we slightly modify D, then we arrive at a modified weight matrix W’ that is an approximation of W instead of W.
SVD Fine-Tuning
If weight matrices can be decomposed into smaller matrices, why bother training for the entire value of W? Instead, we can simply train to get the values of the diagonal in D. If the diagonal elements are a vector d, then more specifically, we multiply a small vector z with d and only z needs to be trained! z is called the scale vector.
This efficient approach to training minimizes the computational power training as only a minimal additional parameters need to be tuned.
On top of that, it seems to require very few samples for fine-tuning compared to LoRA which requires a lot more training samples, marking a significant advantage over existing methods like LoRA.
Inference
Once the model is fine-tuned, inference is done in two-passes as shown in this nice animation from their blog.

In the first pass, the model decides which of the z vectors to use for the given task. In the second pass, it uses the chosen z vector (shown in red above) to do the actual inference for any given prompt. Thus the model is now “adaptive” and it adapts to be a specialist in any given task rather than being a generalist.
Conclusion
The future implications of this research are particularly exciting. As language models become more adaptive and efficient, we might see more specialized applications emerging across various industries, from healthcare to education, each benefiting from models that can dynamically adjust to specific contexts and requirements.
Can’t wait to see what is in store.