Segment Anything Model from Meta AI — Model Architecture, training procedure, Data Engine and Results

If we take a field like Natural language processing, something called the foundational models exist. These models are trained for sequence prediction where the models can predict the next word in a sentence. These foundational models can be easily used for any other NLP task like translation or text summarisation using what is called zero-shot transfer learning. The most well known way to achieve zero-shot transfer learning for a specific task is by prompting with which we have been interacting with ChatGPT. The main reason for the prevalance of such foundational models in NLP is that data is available at scale. Text is everywhere in web and almost all the text can be used for sequence prediction as no labelling is needed for sequence prediction.
Quick Shoutout
If you like this article, why not subscribe to our YouTube channel AI Bites and subscribe to our newsletter too?
Problem with Computer Vision

When it comes to computer vision, even though we have billions of images on the web these days, these images are not labelled with bounding boxes or segmentation masks. And so, establishing foundational models has been challenging.
So can we address this very problem and introduce foundational models for computer vision or more specifically for segmentation so that we can do zero shot learning for a different task using just prompting instead of re-training for the new task? The segment anything model(SAM) does just that and solves this very problem. Lets dive into the working details of the SAM.
Unlike language models, imaging models are special. They take images as input and so how can we prompt a segmentation model? The prompt can be a number of things ranging from say simple point coordinates on a given canvas indiacating where to segment in a given input image. Or it can be one or more bounding boxes or even a rough drawing on the canvas indicating what to segment in the input image. Last but not the least, it could literally be a text prompt explaining what to segment in the image.
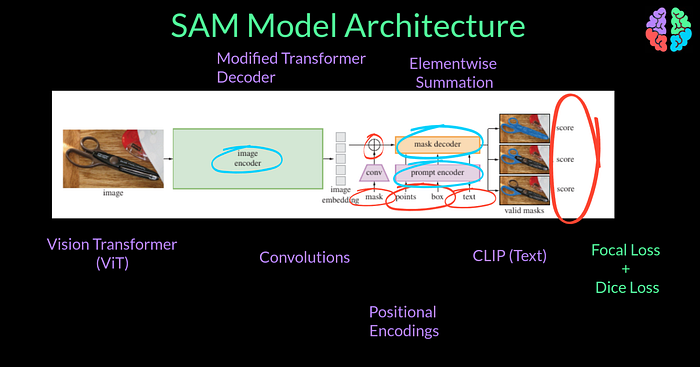
SAM Model
In any case, the model should be flexible enough to handle any of these inputs and output segmentation masks. For this reason, the model architecture has an image encoder which encodes the input image into standard representations called embeddings. These days there are several neural networks available for this task. The choice of encoder by the authors is the Masked Auto-Encoder (MAE) pretrained Vision Transformer that can handle higher resolution inputs.
In order to encode the prompts, they use prompt encoders. If the input is dense such as a rough mask of the object, they use convolution operations. If the input prompt is sparse such as points and boxes, they use positional encodings and lastly if the input is a text prompt, they use CLIP embeddings.
The image and mask embedding are then fused together using elementwise summation and finally put through a decoder as we now have to uplift the embeddings to the size of the image itself to arrive at the segmentation mask. For the decoder they have chosen a modified transformer decoder block.
To train this setup, they use a linear combination of focal loss and dice loss. But at the output, you can notice that there are 3 scores rather a single score for segmentation. Thats to eliminate ambiguity. For this example image, let say you clicked a single point on the scissor’s handle as a prompt. The model doesn’t know if you wish to segment the entire scissors or just the handle. So it makes sense to train for 3 levels of details or granularity and so we have 3 outputs unlike normal segmentation where we only have one output.
Putting all that information together, there is a colourful animation on the sam model website. Whats interesting is that they have made the decoder and prompt encoder extremely light weight and it just takes 55 milliseconds on the web browser without using a GPU.
But the image embeddings are computed only once per image on the server side using the encoder and I am guessing the embeddings are sent back to the browser to be stored in the browser DB so that it can be used any number of times with different prompts in order to avoid computational overheads.
SAM Training Procedure
The training procedure is different from standard training of a neural network because we are aiming to achieve a foundatinal model rather than a segmentation model. So driven by the lack of abundant segmentation data on the internet, they have built a data engine which resulted in a huge dataset of 1.1B masks over 11M images. This data generation system or data engine was developed in 3 stages.
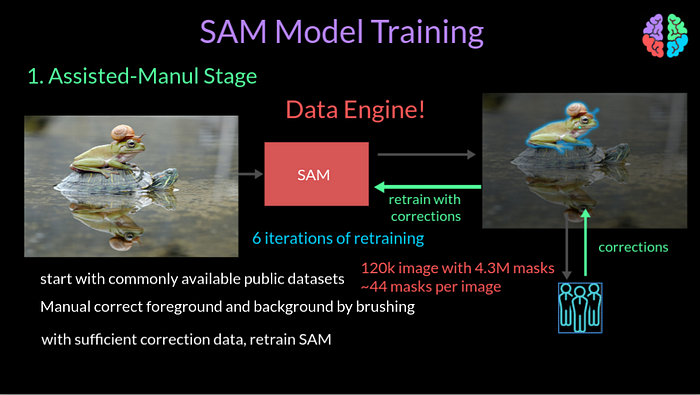
In the first assisted-manual stage, they trained the SAM model with commonly available public datasets for segmentation and let this model interact with manual annotators who used the browser to correct the output masks by erasing and brushing the canvas. After gathering sufficient data, they retrained SAM with this new data. This cycle of periodic retraining was continued 6 times to evolve the final model for this stage. At some point during this iteration, the encoder network size was increased from ViT-B to a larger ViT-H model. After all of this, this stage resulted in 120k images annotated with 4.3M masks. The output masks per image went upto 44 by the end of this stage.
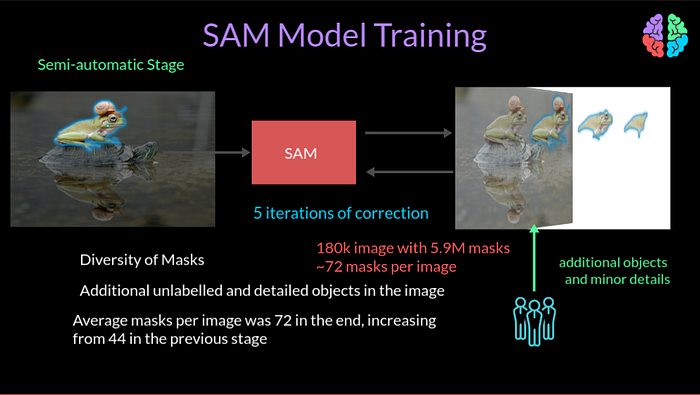
The second semi-automatic stage focusses on improving the diversity of SAM. To improve the diversity, the annotators were asked to label additional unlabelled objects that were much more detailed in the image and so it took longer to label at this stage. By the end of this stage they labelled 180k images with 5.9M masks. Similar to the first stage, they did periodic retraining 5 times during this stage to continuously improve the model. The output masks per image increased from 44 to 72 by the end of this stage.
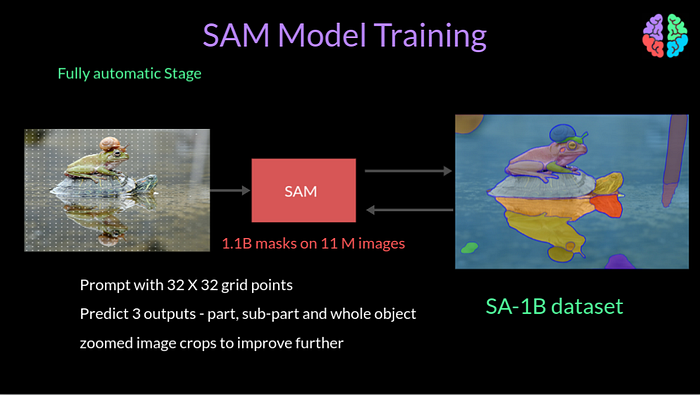
The last fully automated stage introduced prompting at the input with 32 by 32 regular grid of points. The output at this stage would be part, sub-part and whole object. To further refine the quality, they introduced zoomed in image crops. At the end of this stage, they had 1.1B masks on 11M images leading to the SA-1B dataset being generated with 1 billon masks.
SA-1B Training Dataset
One thing to note about the SA-1B dataset is that even though it has 1 billion masks, the of masks are fully automatically generated. The next big point is that the dataset has very high resolution images compared to say COCO dataset. And lastly as seen from this figure, the masks are quite evenly distributed across the image compared to all other previous datasets like COCO or open images
Now that we have the SAM model trained on SA-1B dataset, the model is readily available for Zero shot transfer learning on a novel task. The main goal here is to use the model on a prediction task that it has never been trained for. So our main goal is to produce a valid mask for these tasks. Lets first see what the tasks are.
Zero-Shot Transfer Tasks
Single Point Valid Mask Segmentation is an ill-posed task where we just provide one point as input prompt and the model produces the full mask.. Single point Edge detection is when you input an image and you expect the model to identify the edges in the image. Object proposals are candidates for object detection. In many object detection systems, these proposal are evaluated by the detection model to find out which proposal belongs exactly to the object. Instance segmentation is when you find out each and every object of the same class. In this example the class is a person and the instance segmentation model should identify there are 5 different persons. With those quick explanations of the tasks, lets see the results as to how SAM has performed on each of the tasks.
Model Evaluation
To evaluate the single point mask segmentation, they collated 23 diverse segmentation datasets and compared the performance of a state-of-the-art algorithm called RITM against SAM. These are some sample images from each of the 23 datasets. And these are the reported results which indicate that SAM performs better than RITM in 16 out of 23 datasets. That is quite impressive.

When it comes to the low level vision task of edge detection, they compared the performace transfering SAM on the BSDS500 dataset which is a standard dataset for edge detection benchmarking. The produced results by evaluating 16 by 16 grid points as inputs leading to 768 masks per image. The results in the the figure indicate that the SAM model does not understand which edges to suppress and which edges to keep mainly because this is a general purpose foundation model. Nevertheless, it seems to perform edge detection as shown in this figure from the paper.
Moving on to the mid-level vision task of generating object proposals, SAM was slightly modified to convert the output masks as proposal bounding boxes. Then they used the LVIS dataset to evaluate this task and they compared with the ViTDet object detector model. The obvious metric for comparison here is the Average Recall (AR) and the results indicate that SAM outperforms on medium and large objects and only underperforms when the object are small and occur frequently in the image.
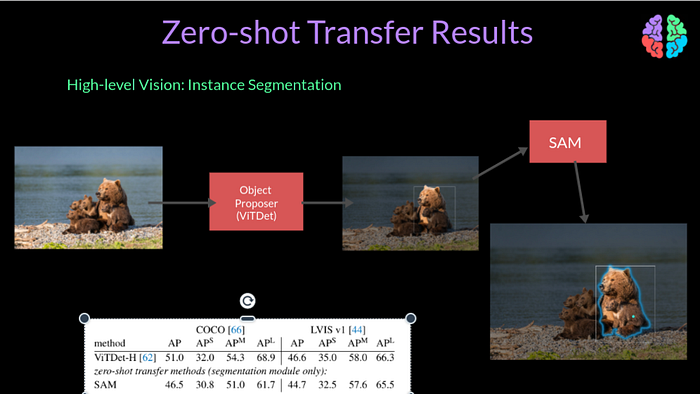
Instance segmentation can be considered a higher level task in the hierarchy of recognition. Making SAM do instance segmenation seems straight forward. You get object proposals from a proposal system like VitDet or something similar and feed the bounding boxes as prompt to SAM model. This results in instance segmentations at the output. Based on the results of evaluation on the LVIS dataset, SAM only slightly under performs compared to the purpose built instance segmentation models.

An even higher level task is to get in put as text prompts and produce mask as the output. They have mentioned themselves that the idea is a proof of concept. In order to cater SAM for this problem, you first get the image embedings from a CLIP model and use those as input to SAM. Now, during inference, because the text and image are aligned in CLIP model , we can simply input the text to the CLIP model and get the segmented image as output. As a result, the SAM model can understand simple prompts. However as seen from this figure from the paper, it seem to do a far better job when guided further with some input points.
Conclusion
The model SAM is just the beginning of a new era of fusing multiple modalities such as Text and Images. Many more systems where all forms of modalities like text, speech and images are fused together to respond in real-time are needed to march towards Artificial General Intelligence (AGI). With all speed at which AI is progressing, we are not far! Lets wait and watch.