RAG — Three Python libraries for Pipeline-based PDF parsing

In the series on Retrieval Augmented Generation (RAG), we have been looking into PDF parsing as a sub-series. In my previous article, we saw about six libraries for rule-based PDF parsing and their pros and cons.
Let's move on to pipeline-based PDF parsing. Here I compare three Python libraries available for building pipeline-based PDF parsers. If you wish to get an overview of PDF parsing, please take a look at my earlier article introducing it.
For all three libraries, I try to parse the file RAG.pdf which is the Retrieval Augmented Generation paper accessible here.
Motivation
As shown by the image below comparing the result of parsing a PDF with Marker and PyPDF, we can clearly notice the need for parsers more sophisticated than PyPDF (which is a rule-based parser we saw in my previous article). Pipeline-based methods can extract formulas, images and tables clearly compared to rule-based methods which fails at extracting even simple images and tables from a PDF file.

Library 1— Unstructured
The strength of unstructured lies in its flexibility. It is on a huge mission to enable organizations to access all of their data to build RAG pipelines. So it is built to ingest many document types such as Word, PowerPoint, PDFs, etc. Let's stick with our focus which is PDFs parsing. Unstructured offers two strategies to parse PDFs, namely fast and high-res. The library can be installed and run locally. We can also install the client side python package unstructured-client which will enable us to invoke their API and go serverless.
Quick Hands-on
To get started there are three options:
- pull a docker image readily available to download
- install using pip and run locally
- go serverless and use the API
While trying out the options, I found using their API to be the easiest. To get started with accessing the API, first, we have to install the python client package.
pip install unstructured-client
We then have to get API access through their site.
We then have to pass the API key and file we would like to process to the below code. Here, I have passed RAG.pdf as filename which is the RAG paper we are working on parsing.
import unstructured_client
from unstructured_client.models import operations, sharedclient = unstructured_client.UnstructuredClient(
api_key_auth=api_key,
server_url="https://api.unstructuredapp.io",
)filename = "RAG.pdf"
with open(filename, "rb") as f:
data = f.read()req = operations.PartitionRequest(
partition_parameters=shared.PartitionParameters(
files=shared.Files(
content=data,
file_name=filename,
),
strategy=shared.Strategy.HI_RES,
languages=['eng'],
),
)try:
res = client.general.partition(request=req)
print(res.elements[0])
except Exception as e:
print(e)
It worked like a breeze and the results are all returned as elements in the response. The different types of elements I found in the result were Title, NarrativeText, Images, Table, etc.
Lets extract the tables and equations to see how well it does. First, the tables,
tables = [element for element in res.elements if element["type"] == "Table"]
Below I have extracted the tables and printed one of them just to visualize how it looks. The table is also returned in HTML format, if we would like to build an HTML page from the returned results.
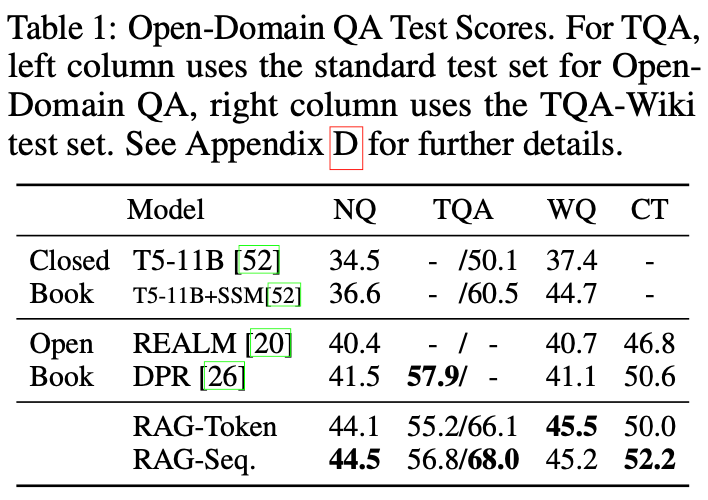
>>> print(tables[0]['text'])
Model NQ TQA WQ CT Closed Book T5-11B [52] 34.5 T5-11B+SSM[52] 36.6 - - /50.1 37.4 /60.5 44.7 - - Open REALM [20] 40.4 - / - 40.7 46.8 Book DPR [26] 41.5 57.9/ - 41.1 50.6 RAG-Token RAG-Seq. 44.1 55.2/66.1 45.5 50.0 44.5 56.8/68.0 45.2 52.2
The above text corresponds to the below table in the pdf:
Let's see how it does with equations which are a plain challenge with rule-based systems. For this, I checked the element of type Formula in the response.
formulas = [element for element in res.elements if element["type"] == "Formula"]
I was keen to see how it does with the equation on page 3 of the RAG paper which is:
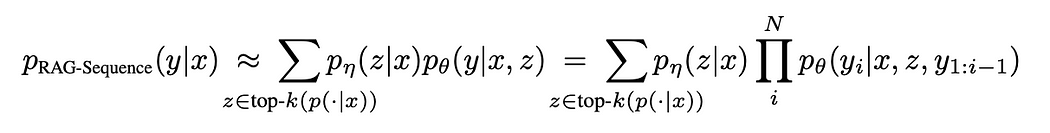
The response I got is as below. It doesn’t look like a clean latex format to me. So I feel it can do a better job with equations.
{'type': 'Formula', 'element_id': '6eb5f70bb678e34c539a0b763fdeca20', 'text': 'Pracseasence (U T) = Y py(2l@)po(yla, 2) = Zp,,(Z\\-T)fipe(yzlmz,yl:zfl) z€top-k(p(-|z)) z€top-k(p(-|x)) i', 'metadata': {'filetype': 'application/pdf', 'languages': ['eng'], 'page_number': 3, 'filename': 'RAG.pdf'}}
Pros & Cons
😃 The library is mature and has good API with sophisticated documentation
😃 It is quite versatile allowing us to parse any docs and can also output HTML, json and other structured formats
😟 As the library encourages API access, it can blow up your cost based on your usage
😟 Not great at dealing with equations
Library 2 — PageMage
Unlike Marker, PageMage is from Allen AI which is a non-profit research institute based in Seattle. It was developed with academic research documents in mind. So I expect it to better at research papers rather than general PDF files.
In terms of design, PageMage uses recipe as a turn-key method to extract all of the document structure from the pdf. These structures are extracted as layers as depicted in the below figure.
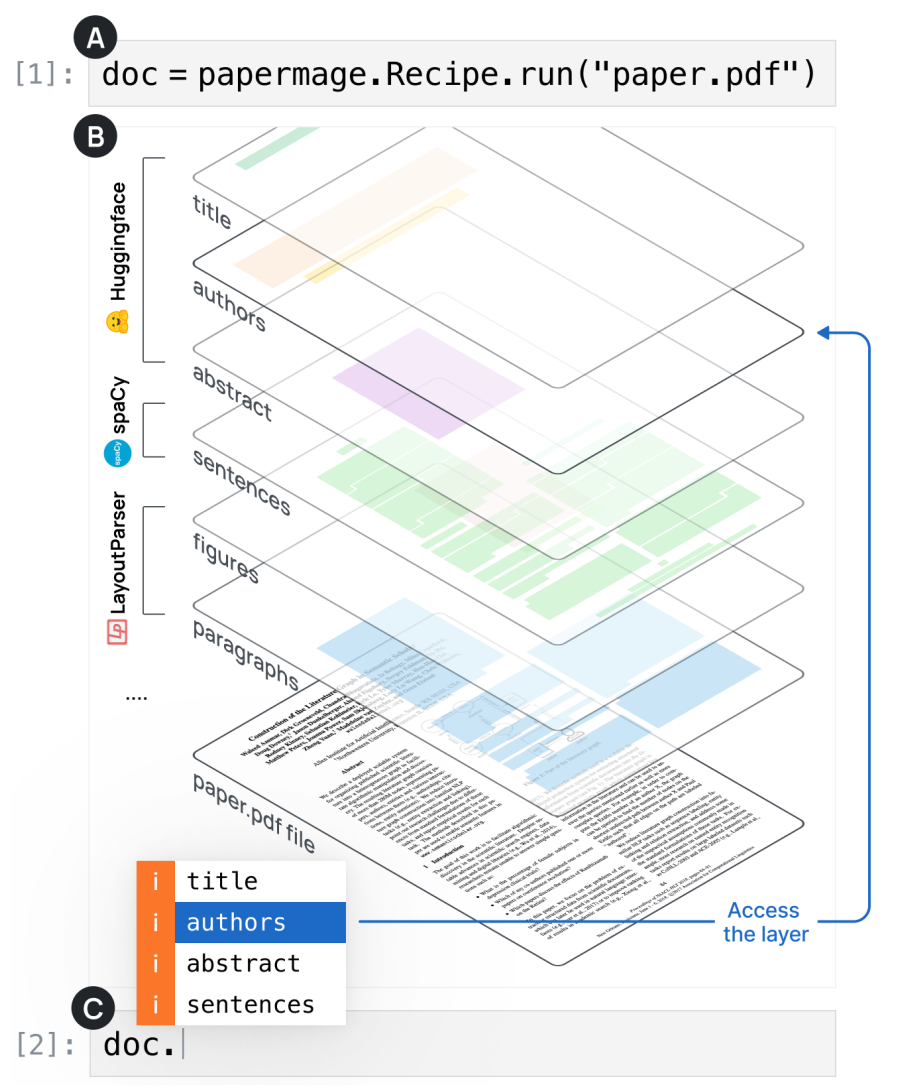
The recipe uses the strength of different libraries available internally. More specifically, it uses HuggingFace models to extract titles, authors, and abstracts. It then uses SpaCy to extract sentences. And lastly LayoutParsers for figures and paragraphs.
As we will see during installation, PageMage is composed of 3 parts: magelib for manipulating visually rich docs, predictors for using ML frameworks to extract figures and layouts, and recipes for combining all modalities and presenting the result. With that said, let's move on to study the practicality and ease of use.
Quick Hands-on
As with any other Python package, I would expect to install it with one line of pip or conda. But it was slightly more involved than that. Firstly it did not install fine with Python 3.10. So I had to create a new virtual environment with python=3.11. Next, on a Mac machine, I also had to install poppler. (this step is mentioned in the readme, however).
pip install 'papermage[dev,predictors,visualizers]'
conda install poppler
As the two installations went through seamlessly, I was expecting it to work like a breeze. However, importing the module lead to errors. All I had to do was, restart the terminal and re-activate the conda environment. Things then worked fine. I managed to run the below commands to get started,
from papermage.recipes import CoreRecipe
recipe = CoreRecipe()
doc = recipe.run("RAG.pdf")
It was really fast to process the entire PDF that it even made me wonder if it even did something! But hurray, it seems to have ripped apart the doc into layers quickly.
>>> doc.layers
['symbols', 'images', 'metadata', 'tokens', 'rows', 'pages', 'sentences', 'blocks', 'figures', 'tables', 'vila_entities', 'titles', 'paragraphs', 'authors', 'abstracts', 'keywords', 'sections', 'lists', 'bibliographies', 'equations', 'algorithms', 'captions', 'headers', 'footers', 'footnotes', 'Figure', 'Table']
Just to double-check, I printed the authors from the paper and it seems to have extracted them perfectly,
>>> print(doc.authors)
Layer with 1 Entities:
Annotated Entity: ID: 0 Spans: True Boxes: True Text: Patrick Lewis †‡ , Ethan Perez (cid:63) , Aleksandra Piktus † , Fabio Petroni † , Vladimir Karpukhin † , Naman Goyal † , Heinrich Küttler † , Mike Lewis † , Wen-tau Yih † , Tim Rocktäschel †‡ , Sebastian Riedel †‡ , Douwe Kiela † † Facebook AI Research; ‡ University College London; (cid:63) New York University; plewis@fb.com
Let’s now see how we are doing with tables and equations. For tables, lets print the same table that we printed with unstructured.
print(doc.tables[0])
Annotated Entity: ID: 0 Spans: False Boxes: True Text: Model NQ TQA WQ CT ClosedBook T5 - 11B [ 52 ] 34 . 5 - / 50 . 1 37 . 4 - T5 - 11B + SSM [ 52 ] 36 . 6 - / 60 . 5 44 . 7 - OpenBook REALM [ 20 ] 40 . 4 - / - 40 . 7 46 . 8 DPR [ 26 ] 41 . 5 57 . 9 / - 41 . 1 50 . 6 RAG - Token 44 . 1 55 . 2 / 66 . 1 45 . 5 50 . 0 RAG - Seq . 44 . 5 56 . 8 / 68 . 0 45 . 2 52 . 2
It has surely extracted the numbers. But as with unstructured, it doesn’t provide the optional HTML format which could be handly at times.
Moving on to equations, lets print the equation in page 3 of the paper. Firstly, it doesn’t extract formulas as a separate layer. But I found the below line along with the text for page 3 in the parsed document.
p RAG-Sequence ( y | x ) ≈ (cid:88) z ∈ top- k ( p ( ·| x )) p η ( z | x ) p θ ( y | x, z ) = (cid:88) z ∈ top- k ( p ( ·| x )) p η ( z | x ) N (cid:89) i p θ ( y i | x, z, y 1: i − 1 )
This doesn’t look like the latex format to me. Moreover, equations get interleaved between the extracted text rather than being extracted as separate layers.
Pros& Cons
😃 The library is super quick and does everything locally
😃 It specializes at research papers
😟 struggles with formulas and equations, particularly seggregating them into a separate layer
Library 3— Marker
Marker is a library for converting PDF, epub, and mobi files into Markdown. The official repo is available here. Unlike the other two libraries developed by organizations, marker seems like a hobby project. I works alongside surya for OCR.
It works by following the below steps:
- Extract text, OCR if necessary (using surya, heuristics or tesseract)
- Detect page layout and find reading order (again using surya)
- Clean and format each block (using heuristics, textify)
- Combine blocks and post-process complete text (using heuristics, pdf_postprocessor)
Let's give Marker a quick spin to test its capabilities.
Quick Hands-on
We can install marker with pip. Though there is a dependency on PyTorch, lets hope to get away with a CPU only laptop, without a GPU. Let's test it out with the RAG paper as we tested the rule-based frameworks.
pip install marker-pdf
As provided in their documentation, we can get started by simply loading the models and passing our RAG.pdf to the models.
from marker.convert import convert_single_pdf
from marker.models import load_all_models
fpath = "RAG.pdf"
model_lst = load_all_models()
full_text, images, out_meta = convert_single_pdf(fpath, model_lst)
The above step took significant time on Mac and actually ran out of memory on an 8 GB RAM Macbook Pro. It's largely due to the models the framework is loading to process the PDFs.
Fret not as we have their API and it's free for individuals and small companies. From trying it out for a while, I found that the API is still in active development. I wasn’t able to successfully access it with ease. So, we need to give Marker some time before we can reliably put it to use in production! Let's look at the pros and cons before moving on.
Pros & Cons
Though we couldn’t thoroughly test it due to its inherent challenges with usage, we have safely compiled the below points from other sources:
😟 Marker is not the best at converting complex equations to LaTeX.
😟 Tables are not always formatted 100% correctly, particularly those with a lot of text
😟 Indentations are not always respected.
😟 Though it can handle images of docs as PDFs, it is best for digital PDFs that require no OCR in the pipeline.
But on the positive side,
😃 Marker is open source and API access is fast emerging
😃 It promises to work with any language and not just English
Verdict
The PDF parsing space is clearly maturing and moving at a fast pace to keep up with more exciting developments in LLMs and RAG. But we do need sophisticated data ingestion tools to make life easier with RAG.
From my quick research, I have concluded the below about these three pipeline-based libraries.
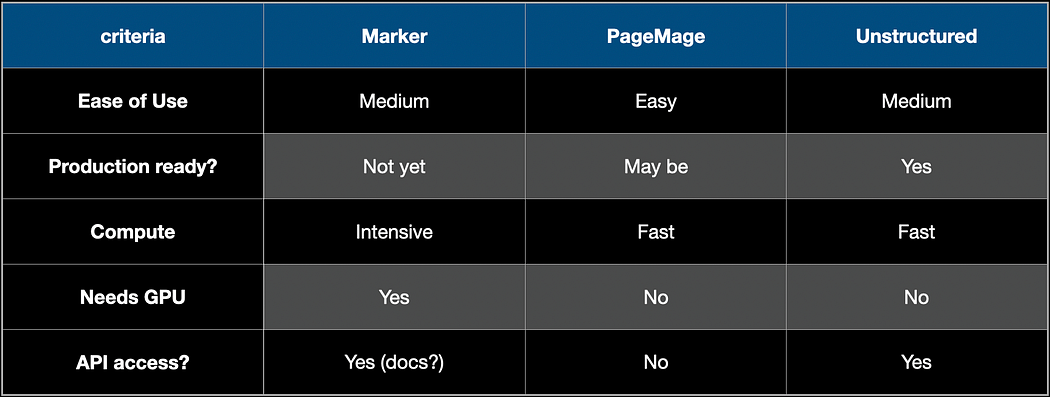
Let me know if I have missed some details leading to skewed opinions or if I can add any other libraries that are pipeline-based. Your comments are most welcome!