MusicGen from Meta AI — Model Architecture, Vector Quantization and Model Conditining explained

MusicGen or Simple and Controllable Music Generation is the latest work from Meta AI which promises to generate exceptional quality music using a single language model architecture. It achieves this using an efficient token interleaving technique. Despite generating music for a max duration of 8 seconds, it has the potential to be conditioned by text or melody as prompts to control the output generated.
The architecture is built on top of the EnCodec project proposed by Meta in late 2022. The architecture still has an encoder, quantizer and a decoder However, MusicGen has additional conditioning modules to handle text and melody input prompts. Lets dive deeper into MusicGen architecture starting from vector quantization, the decoder and the conditioning modules that are integrated with the decoder.
Encoder
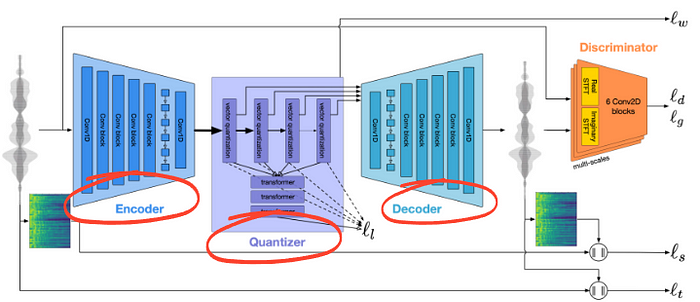
As MusicGen is built on top of the EnCodec architecture, lets start by understanding Encodec and learn what has changed. The end-to-end architecture of EnCodec has 3 parts namely encoder, quantizer and decoder. The encoder is fairly straightforward like in any other auto-encoder module and it has not been changed much in MusicGen. It is a standard convolutional architecture which churns out a vector representation for every frame in the input.
The next step after encoder is Residual Vector Quantization (RVQ). Before understanding RVQ, lets understand Vector Quantization(VQ) which is a precursor to RVQ.
Vector Quantization
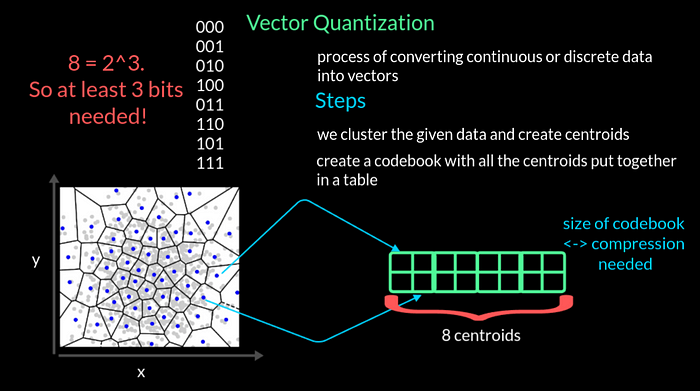
Simply said, VQ is the process of converting continuous or discrete data into vectors. The key goal of quantization is to get a compact representation so that we achieve data compression. There are 3 steps involved in the process. To understand it, lets take a look at 2 dimensional data with dimensions x and y. First, we cluster the given data and get the centroids of each cluster that are shown as blue dots. We can now put together all these centroids in a table. This resulting table is called a codebook. Needless to say, the more the centroids the larger the table has to be to capture all the centroid values. In this toy example, lets say we have 8 centroids. The number of bits needed to uniquely represent 8 centroids is 3 as 2 power 3 is 8. So we at least need 3 bits per second budget to compress this 2D data with 8 centroids.
There is a twist however to this codebook which is that the size of this codebook depends on the target level of compression we need to achieve.
Vector Quantization and its limitations

Lets look at a practical example to understand the limitations of vector quanitization. Lets say that the target budget is 6000 bits per second. we need to compress the input audio within this budget. Lets say we are getting the input data at the rate of 24,000 Hz. And we are down sampling or striding this with a factor of 320. As a result, we get 75 frames per second. So, in order to achieve 6000 bits per second at the output, we have to allocate 80 bits for each frame. This enforces a constraint on the codebook that the size of the codebook or the number of centroids has to be at least 2⁸⁰. 2⁸⁰ is a very high number. Lets also not forget that practically, each frame is going to be the output of an encoder network and so its dimension is going to be about 128 dimensions. And this complexity only increases if we want to improve the quality of quantisation. So in summary, the complexity of vector quantization increases in no time and so we have to use a more practical quantisation technique.
Residual Vector Quantization
The solution to this problem lies with RVQ. Here residual implies multi-stage quantisation. Instead of having one codebook, we can now have N_q codebooks where N_q is the number of quantisers and is a number we choose.
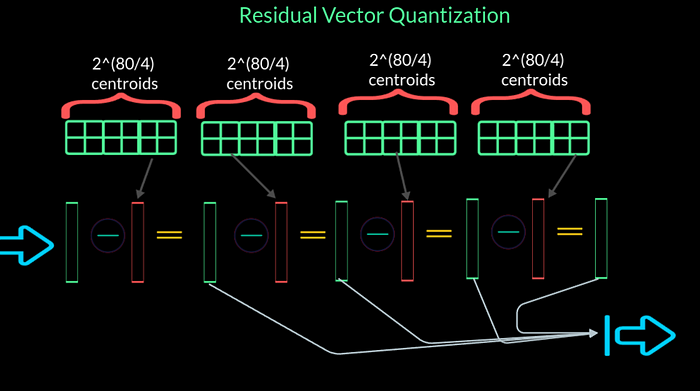
We have illustrated with 4 codebooks but in MusicGen implementation there are 8 codebooks. The idea is that we use the input and the first codebook to get the first quantised output from the first codebook. This output is then subtracted from the input and it gives the resudual for that stage. This residual is then passed to the next codebook to obtain its output and so on and so forth at each stage. One thing to note is that the number of centroids per codebook has reduced from 2 power 80 to 2 power 20. If we choose N_q as 8, then this number further reduces to 2 power 10 which is 1024. So we will get one output for each of the codebooks used. We can either add them up or use as a single output or we can process them in other ways. The way MusicGen addresses these is by using interleaving patterns.
Interleaving Patterns
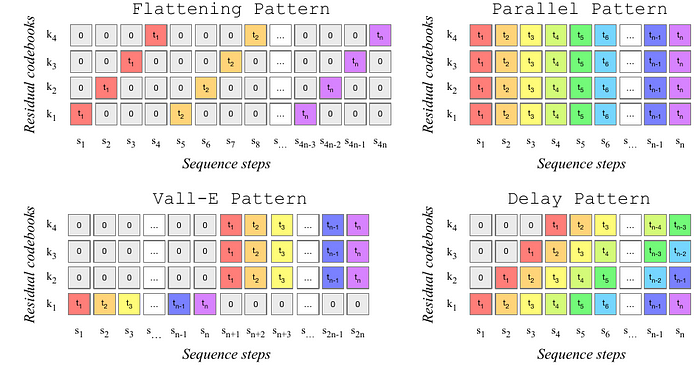
Now that we get 4 outputs k_1, k_2, k_3 and k_4 per input frame from RVQ, there are different ways we can order them or interleave them before we feed them into the decoder. Lets look at the standard way of doing this which is simple flattening. For each time step t, for example t_1, we get 4 outputs. These can be simply flattened to form s_1 to s_4. Then we take the four outputs for time t_2 and lay them flat to fill the sequence step s_5 to s_8. This way of simply laying everything in sequence is flattening pattern.
Then there is a parallel pattern where for a given time t, we literally stack the outputs of all 4 codebooks one on top of the other for each sequence step s. For example, s_1 has all the 4 outputs of timestep t_1.
Then there is delayed pattern where we introduce 1 step delay per codebook to indicate the order of the codebook itself.
Then there is a more promising pattern that has been adopted from the Vall-E paper which is that we prioritise the output of the first codebook for all the n time steps. Then we switch to parallel pattern for rest of the codebooks. For this reason this pattern takes twice the sequence steps size compared to the other patterns.
Codebook Projection and Positional Embedding
Lets take the flattening pattern example to learn how these codebook patterns are used. Lets say we are at sequence step s2. We first note down what codebooks are involved in that particular step. In this example its K2. As we have access to all the codebooks, we can always retrieve the values corresponding to the indices. The values for each sequence step are summed up to form the representation for that sequence step. Additionally, a positional embedding using a sinusoidal is also summed to each time and the summed values are passed to the decoder. If you have doubts about positional embedding, we have made a video about it. You can always look at it and come back to this video.
Model Conditioning with Text and Audio
The speciality of MusicGen is that there is the ability to condition either with text or with any melody like whistling or humming. If the conditioning is text, they have chosen to use one of the 3 for encoding the txt. First, they explore a pretrained text encoder T5 which stands for Text-to-Text Transfer Transformer and was published sometime in 2020. Then they also try FLAN-T5 which is was released in this paper, Scaling Instruction-Finetuned Language Models. There are also claims that combining text and audio for conditioning would do a far better job. So they explore that option dubbed CLAP.
If we were to condition on melody such as whisling or humming, we should train with that information as well. For this, one option is to use the chromogram of the conditioning signal. The chromagram consists of 8 bins. When the chromogram is used without modification for training, it seems to overfit. So we suppressed the dominant time-frequency bins and leave rest of the data to be used for training.
Decoder
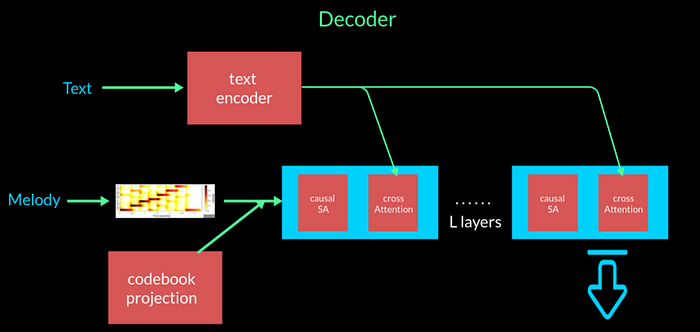
These codebook projections along with the positional embeddings are then passed to a transformer based decoder. There are L layers in the decoder with each layer consisting of a causal self-attention and cross-attention block. The decoder additionally takes as input the conditioning C which can either be text or melody . If its text, the cross attention block that takes the conditioning signal C after the text has been encoded by a standard encoder say T5. If its the melody, they pass the conditioning tensor C as prefix to the transformer input after being converted to a chromogram and preprocessed. As a result we get the output music that is generated, conditioned on the condition C.
And that is how MusicGen generates music conditioned of either text or melody.
I hope that was useful. Don't forget to watch the video. See you in my next ...