Mixture-of-Transformers for Multi-modal AI

The future is multi-modal. At least, that is what I strongly believe in.
As we know by now, the one architecture that singularly reigns the LLMs and shook the world through ChatGPT and similar work is the Transformers. But sadly, transformers are designed with text modality in mind. No wonder Yann Lecun mentioned in one of his LinkedIn posts, we are seeing a “plateauing of performance”.
One solution to the plateauing could be to redesign the transformers to deal with multiple modalities so that learning from one modality can enrich learning from another. Take videos for instance. Simply watching a video makes no sense for humans unless we “hear” the audio along with it. So, it is no surprise that we do need multi-modal models to develop better AI systems.
Meta AI has come up with Mixture-of-Transformers, an architectural novelty to revamp transformers and make them multi-modal!
Visual Explanation
If you are like me and would like the MoT explained visually, please checkout this video:
Motivation
Though the main problem with transformers is that it is designed for text, there is another dimension to it. Multi-modality comes with an enormous amount of data — more than all the text available on the internet. Because we are now talking text, speech, images, and videos on the internet!
So we need to have a light-weight transformer that can deal with this scale of data. Though Chameleon and Mixture-of-experts have been proposed, they disregard the computing power required to train these models.
Mixture-of-transformers introduces sparsity to the transformer architecture and addresses the training computation challenge.
Model
Lets look at the typical way we deal with foundation models followed by the Mixture of Tranformer(MoT) architecture.
Typical Multi-Modal Foundation Models
If we take a typical multi-modal foundation model, we feed them the tokens for different modalities by interleaving them.
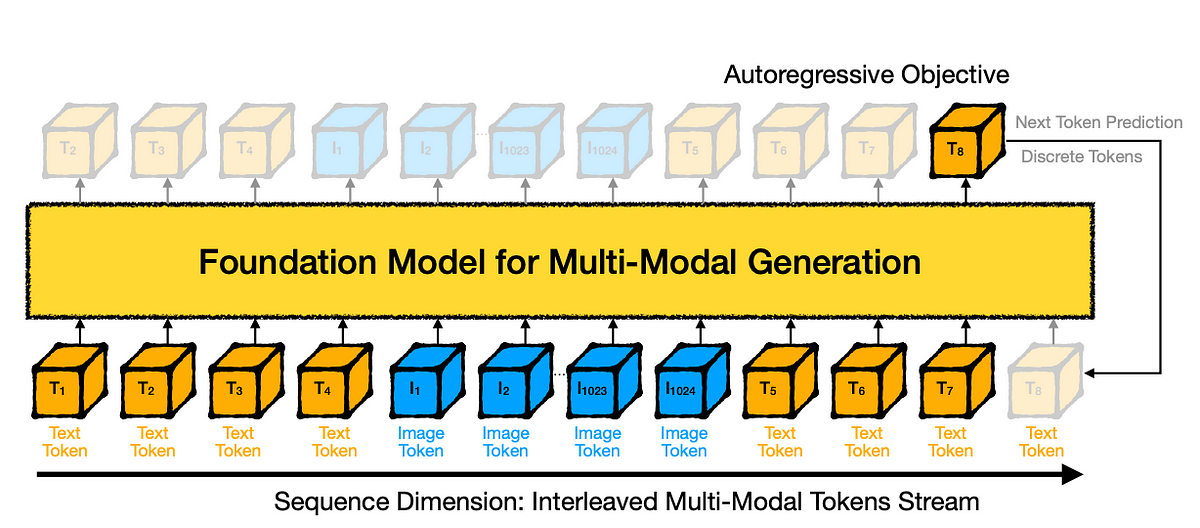
As shown above, we feed the text token and then interleave the image token with them and we alternate the different modalities in the input during training. We have the autoregressive objective to train this model in the pre-training stage.
Clustering of Features
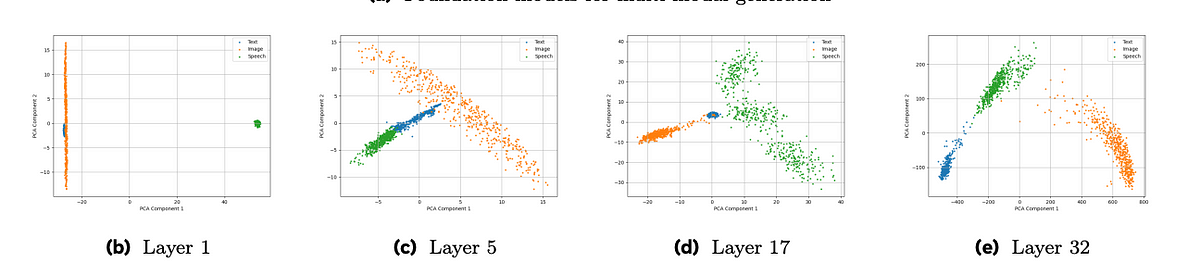
This way of interleaving doesn’t mean that the model is not distinguishing between the different modalities. It can be witnessed by the Principal Component Analysis (PCA) visualization of the features of different intermediate layers. The features are clearly separated/clustered into speech, text, and images. This motivates us to introduce separation in the transformer architecture itself. As an add on, such a separation could mean sparsity and less training compute. So it should be a win-win situation.
Mixture of Transformers(MoT)
MoT tried to address the limitations of transformers for multi-modality. It has the below architecture.
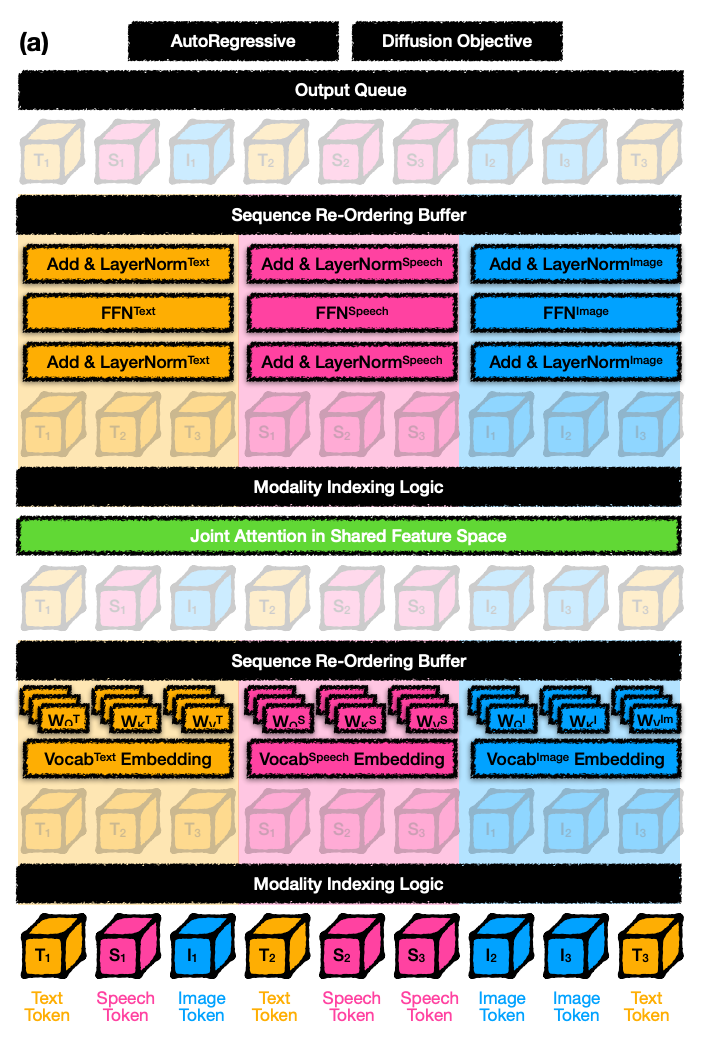
We start with the natural sequence of the input modalities (text, speech and images tokens). We introduce simple indexing to track where each of the modalities occur. The indexed tokens are then grouped and then treated separately. When I say treated separately, we have separate weights for each of the Query(Q), Key(K), and Value(V) for each of the modalities.
The output sequence of this layer is then reordered using the indices to restore to original order. They are then fed to the Global Attention layer (shown in green in the figure). After attention, the sequence is once again grouped as per modality to feed the layer norm and feed-forward network before gathering the output.
Results
The main motivation to do all this is to introduce sparsity and to improve the training time. So lets see if we have achieved that. Below is the result reported in the paper.
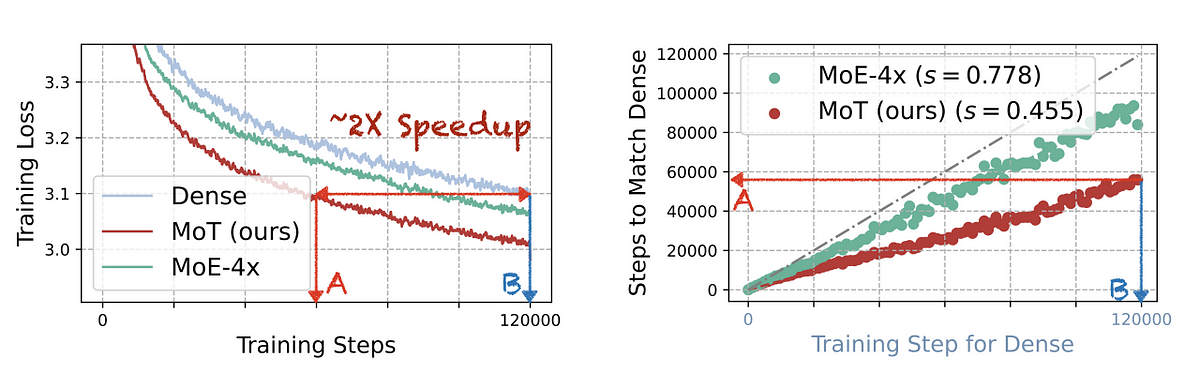
First, the appradch seems to achieve 2X speedup. We are able to reach the same training loss as a dense transformer in half the time with the MoT model.
Second, the training steps are also halved. What the dense and Mixture-of-Expert(MoE-4x) models take to achieve in 120,000 steps, the MoT model is able to achieve in 60,000 steps.
They have done the experiments in 3 settings and found similar results:
- Chameleon (state-of-the-art model with text + images)
- Chameleon + speech
- Transfusion (transformer + diffusion objective)
Empirical Analysis
The test of the compute capabilities of the model, they do
- horizontal scaling — increase the GPU available for computing from 16 to 256 in gradual steps and see how well the model scales with computation available at our disposal
- Wallclock time — if we fix the number of GPUs and the time allocated to train the model, which is the best model?
With horizontal scaling, they found that the percentage of steps required for MoT to match the image validation loss of the dense model (trained with the same number of GPUs) decreases from 42.1% to 21.6%.
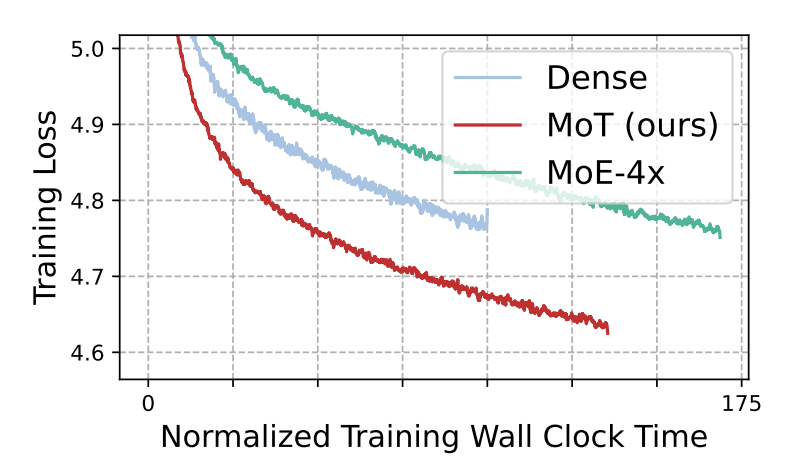
As can be seen above, with the fixed wall clock time, we can see that MoT converges way faster than the MoE and Dense(Cameleon) models.
Conclusion
I have tried my best to simply the 34-page long paper. Obviously, I have stripped the idea to the bare bones. If you wish to deep-dive and read the entire paper, here it is.
Its really exciting to see any form of advancement in the multi-modal space as I strongly believe that the future is multi-modal. Just as humans intelligence is non-existant without a mix of speech, images and text, so is AI without a mix of all modalities. I simply cannot wait to see whats coming up next in multi-modality.
See you in my next …