Lumiere — The most promising Text-to-Video model yet from Google

Would you like to see Monalisa smile like a witch? Or would you like the girl with the pearl earring to wink and smile? Google has just dropped a video generation model named Lumiere [1] that's capable of doing all of it for you. Though it's primarily a text-to-video model, it's able to do much more than that. Given a reference image with a prompt, it can stylize your videos by copying the style of the reference image to your videos. You can even edit your videos with just a single prompt. The model is Lumiaire. It's even able to animate objects within a user-specified region in an image, a technique called Cinemagraphs. When it comes to inpainting, Lumiere is even able to reason about a completely missing object such as a cake in this example.
It all boils down to a diffusion model with a novel space-time U-Net architecture [3]. It's a customization of the U-Net architecture to solve the problem of temporal consistency which is quite prevalent in video generation models.
Visual Explanation
A visual explanation of the Lumiere paper, the model architecture, and the results are available here
So what is temporal consistency?

We all know that videos are a sequence of images. So let's take a sequence of images shown in the top row in the above figure. If we narrow down just one row in the image, which is indicated by the green line going from left to right, we need to see a smooth transition in the pixel values between images in the sequence. If the transition is smooth, then we won’t see a jumping effect while we are watching the video.
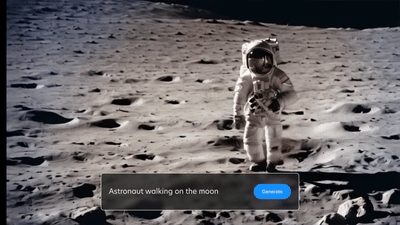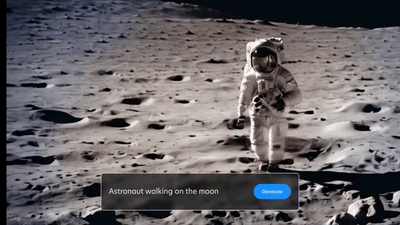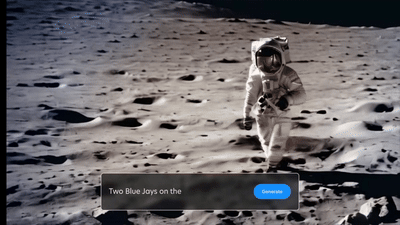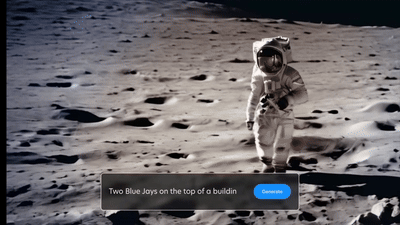
For example, if we take Stable Video Diffusion [2], and see the video of an astronaut walking on the moon (above), we can see that his hands just disappear between frames. In other words, the temporal consistency between frames is lacking.
This kind of temporal inconsistency between time and the intensity in the x direction can be plotted as the X-T Slice as highlighted in the figure above. And if there is temporal inconsistency, it is highlighted in the plot of the X-T slice.
Lumiere addresses this problem by introducing a space-time diffusion model and a modified U-Net architecture present in the diffusion model.
Pipeline of a Text to Video
Before looking into the details, let's start with the typical pipeline of a Text-to-video generation model.
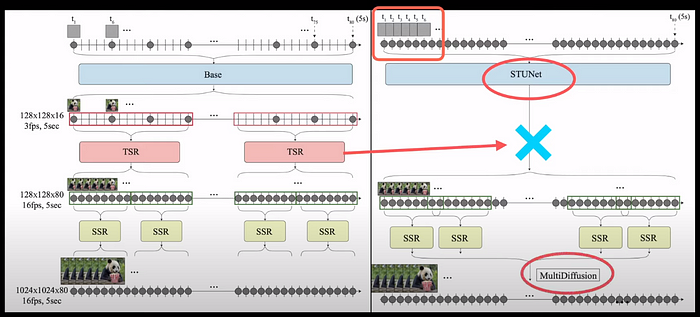
These pipelines sample every 5th frame as the keyframes from the input video sequence and train a base model that can generate these keyframes at a resolution as low as 128 by 128 at just 3 frames per second. Then temporal Super Resolution is used to increase the frame rate by predicting the intermediate frames. So the frame rate now becomes 16 frames per second. The spatial resolution of these frames is then increased to say 1024 by 1024 by a spatial superresolution network (SSR) which finally leads to our generated video.
The base model used in this framework is usually a diffusion model which in turn has a U-Net inside it.
The proposed pipeline of Lumiere
The proposed pipeline of Lumiere on the other hand processes all the frames at once without dropping frames. To cope with the computational cost of processing all the frames, the architecture of the base diffusion model is modified to come up with the space-time UNet architecture or STUNet. As STUNet deals with all the input frames, the need for Temporal Super Resolution or TSR is eliminated. So The pipeline still has the spatial super resolution or SSR. But the novelty is the introduction of MultiDiffusion.
From U-Net to STUNet
Let's quickly review the U-Net before looking into the space-time U-Net. The input to the U-Net is a 3 3-dimensional image with Width W, Height H, and channels RGB. After every double convolution stage of the U-Net, we apply max pooling to downsample or reduce the spatial dimension of the features. This spatial dimension reduction step is indicated by the red arrows. Similarly, during the decoder stage, there are up convolutions to increase or upsample the resolution back to the size of the input.
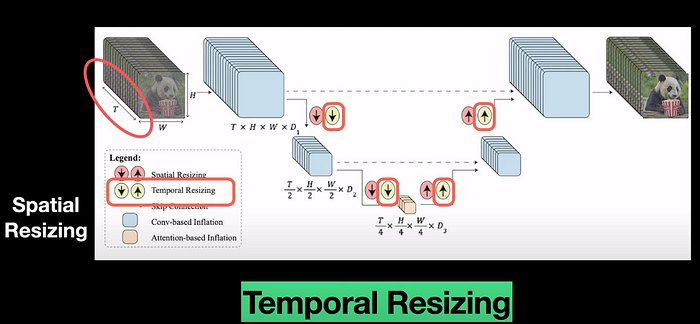
When it comes to videos, we have an additional dimension in the input which is time. so space-time U-Net proposes to downsample and up-sample the video not only in the spatial dimension but also in the dimension of time T. This is the main idea of temporal resizing and is the main contribution of this Lumiere paper. For resizing, they use 3D pooling instead of 2D pooling as the input now has an additional dimension.
Like me, you may be surprised by the simplicity of the idea. The authors themselves have mentioned in the paper:
Surprisingly, this design choice has been overlooked by previous T2V models, which follows the convention to include only spatial down and up-sampling operations in the architecture, and maintain a fixed temporal resolution across the network.
Implementation
Let's get to some of the nuances of the implementation. They use factorized convolution introduced in this paper called Video Diffusion Models. The idea is to change each 2D convolution into a space-only 3D convolution, for instance, by changing each 3x3 convolution into a 1x3x3 convolution. For the attention, after each spatial attention block, we insert a temporal attention block that performs attention over the first axis and treats the spatial axes as batch axes.
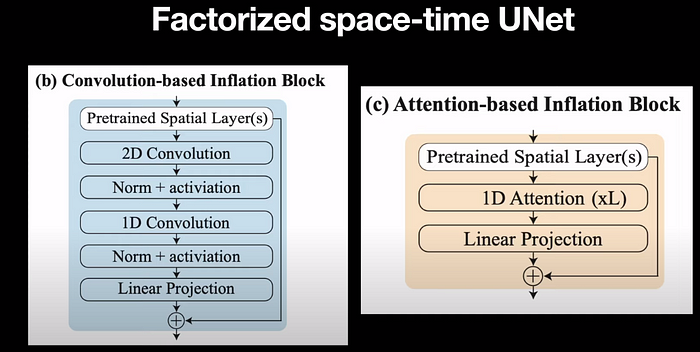
With those two changes, the factorized convolution blocks are added to the pre-trained model and only the additional layers are trained with the pre-trained layer weights fixed.
The second novelty of the paper is the MultiDiffusion introduced during the spatial superresolution. If you take the video generation models before lumiere, the spatial superresolution model takes a sequence of frames. However, the sequences were not overlapping. For example, the first 8 frames and the next 8 frames taken as input by the SSR module are separate without any overlap.
But when it comes to Lumiere, the first 8 frames and the second 8 frames have an overlap of two frames. By doing this, the spatial super-resolution model seems to achieve smooth transitions between the temporal segments. This is what is referred to as multiDiffusion in the paper.
Applications
Coupling the two proposed techniques along with the absence of a cascaded diffusion model architecture which is prevalent in prior architectures such as imagen video, leads to quite a few varied applications.
For example:
- the model can convert text to videos with prompts such as “an astronaut walking on planet Mars making a detour around his base” or “a dog driving a car wearing funny sunglasses”.
- the model can convert images to videos along with a text prompt such as, “A girl winking and smiling”.
- it can stylize generation with a reference image and a text prompt such as, “a bear dancing”.
- talking of Cinemagraphs, it can animate regions selected by the user such as fire or steam. It can even edit dresses that people are wearing with just a single prompt.
Evaluation
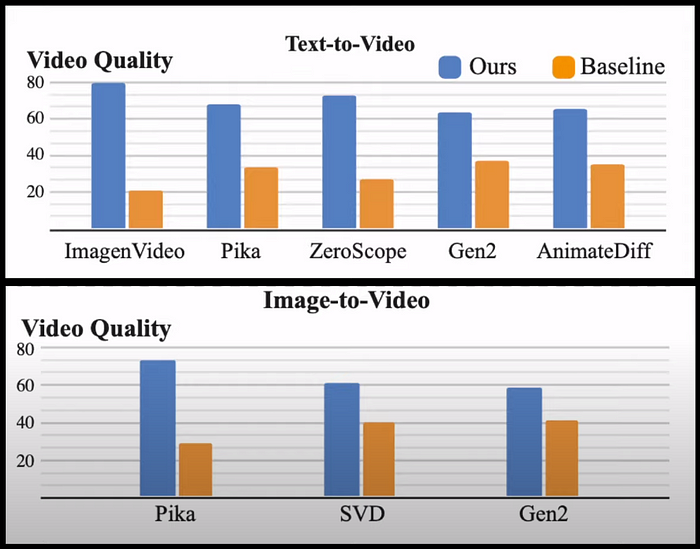
To evaluate the model quantitatively, the model was run through a user study where the users compared the results of the proposed model against some state-of-the-art models such as Pika, ZeroScope, or stable video diffusion. The results indicate that the users preferred the Lumiere model both in the case of text to video and image to video.
Conclusion
So to conclude, other than all the promotional video stunts, such as the smiling Monalisa, the contribution of this paper is fairly simple. Put in one line, the paper introduces a downsampling of the temporal channel. This coupled with MultiDiffusion which is nothing but having overlapped frames fed into the superresolution model generates high-fidelity videos that are temporally consistent.
What I would have liked to see is some ablation studies in the paper showing the results with and without the multiDiffusion process.
That brings us to the end of this article. The next time someone talks to you about Lumiere, you know what to say in one line. I hope that provided some insight into the Lumiere model.
I will see you in my next, until then, take care…
References
[1] Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Herrmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Yuanzhen Li, Tomer Michaeli, Oliver Wang, Deqing Sun, Tali Dekel, Inbar Mosseri, A Space-Time Diffusion Model for Video Generation (2024), arXiv preprint.
[2] Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, Varun Jampani, Robin Rombach, Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets (2023), arXiv preprint.
[3] Olaf Ronneberger, Philipp Fischer and Thomas Brox, U-Net: Convolutional Networks for Biomedical Image Segmentation (2015), International Conference on Medical Image Computing and Computer-Assisted Intervention.