Developing an Alexa-like AI assistant running locally on my laptop

With all the sophisticated tools and libraries such as LangChain, Ollama, and StreamLit, developing an AI app can’t get simpler. All that we need is basic Python skills and familiarity with some tools to load and run AI models.
This weekend, I managed to develop the app below in less than a day.

In this article, I am going to walk you through the steps I used to develop this very app. The entire code is available on GitHub for free here:

Visual Explanation
If you are a visual learner like me, then please check the video below that walks through the code:
Workflow of the app
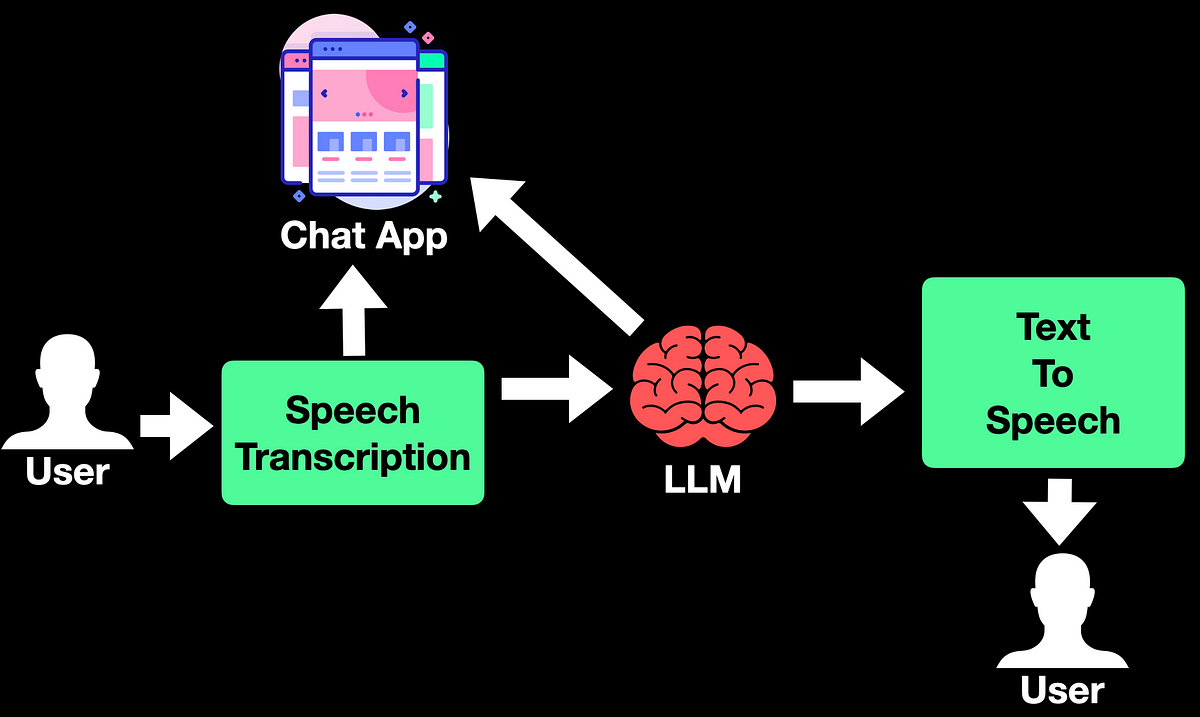
The end-to-end workflow is fairly simple. The users first talk to the app with their query. The query is first processed by a speech transcription model. We use the Whisper model from Open AI for this. The transcribed text is passed to the UI for display.
At the same time, the transcribed text is fed to the LLM for a response. The choice of LLM is the Llama 3.1 model, though we can go for any open-source model here. The response from the LLM is fed to the text-to-speech step.
Google’s text-to-speech API is the choice for this. The response from the API is both stored and spoken out as an audio response.
Development Steps
Below are the steps that I followed to develop the app. I have oversimplified the explanation here. But I walk through the steps in depth in the posted video.
Step 1 — UI using StreamLit
One of the simplest, easiest, and fastest ways to pull up a UI in Python is using StreamLit. We don’t have to worry about CSS and browser compatibility. It's all taken care of. Below is the code for the page title, side panel, chat messages, and voice input button/icon.
st.title("Locxa - I'm your local Alexa ;-)")
st.session_state.model = st.selectbox("Model", ["llama3.1", "llama3.2:latest"], index=0)
st.session_state.temperature = st.slider("Temperature", 0.0, 1.0, 0.0, 0.05)
st.session_state.max_tokens = st.slider("Max Tokens", 100, 5000, 500, 100)
# to display previous messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# Voice input
footer_container = st.container()
with footer_container:
st.session_state.audio_bytes = audio_recorder(text="Click to talk: ", icon_size="lg")
Step 2 — Transcribe the input speech
One of the best models currently available for speech transcription is OpenAI’s Whisper model. So I chose to use it for transcribing the speech that the user provides.
def transcribe_audio(pipeline, audio_bytes):
"""Speech to text conversion"""
ip_audo_file = "ip_audio.mp3"
with open(ip_audo_file, "wb") as f:
f.write(audio_bytes)
transcript = None
if os.path.isfile(ip_audo_file):
try:
result = pipeline(ip_audo_file)
transcript = result['text'].strip()
return transcript
except:
print("Did not process speech very well!")
return transcript
Step 3 — LLM for text responses
When we are doing any open-source stuff, Llama or any of its derived models is the go-to option. For this reason, I chose to use the Llama 3.1 version for any response to the user queries.
As we plan to run the app on a laptop, we need to use a quantized version of the model. Fortunately, the quantized version is available on the Ollama ecosystem. So I installed Ollama on my Mac machine from here and pulled the Llama 3.1 model for use from here.
After running the Llama 3.1 model with the Ollama run llama3.1 command, we are set to use it in our app.
class ChatBot:
def __init__(self, model, temperature, max_tokens) -> None:
self.llm = ChatOllama(
model=model,
temperature=temperature,
max_tokens=max_tokens,
)
self.prompt_template = ChatPromptTemplate(
input_variables=["content", "messages"],
messages=[
SystemMessagePromptTemplate.from_template(
"""
You're a Personal Assistant, named Locxa.
Give short and concise in about 50 words, but always provide a full sentence.
"""
),
MessagesPlaceholder(variable_name="messages"),
HumanMessagePromptTemplate.from_template("{content}"),
],
)
self.memory = ConversationBufferMemory(
memory_key="messages",
chat_memory=FileChatMessageHistory(file_path="memory.json"),
return_messages=True,
input_key="content",
)
def create_chain(self) -> LLMChain:
chain = LLMChain(llm=self.llm,
prompt=self.prompt_template,
memory=self.memory)
return chain
As can be seen above, ChatBot is the main class that takes care of loading the model, and has the prompt template and the model parameters. Once we initialize this class with the right model and its parameters, we need to create a chain using the LLMChain class from LangChain. We use that chain to get the response from the LLM (Llama 3.1).
Step 4 — From text to speech
Now that most of the job is done, it all comes down to simply speaking out the text generated by the LLM. For this reason, I chose to use Google’s text-to-speech API to simplify our job. All that we have to do is use the GTTS function from the API and pass the text to get the speech back as shown below.
def text_to_speech(text):
# Save the converted audio in a mp3 file named
language = 'en'
tts = gTTS(text=text, lang=language, slow=False)
tts.save("output.mp3")
# play the stored audio
if platform.platform().startswith("mac"):
os.system("afplay output.mp3")
else:
os.system("aplay output.mp3")
Conclusion
Though the app mimics Alexa in its functionality, I have oversimplified the explanation for the sake of this article. There is a lot going on under the hood. Particularly, a decent understanding of LangChain and Ollama for LLM development is essential to pull through an app like this in no time. It is a testament to the fact that the field is progressing so fast with such sophisticated libraries. This is just a simple example to study and show what is feasible with today’s tools and libraries. A lot remains to be done to make it better and any PR’s to the GitHub repo are more than welcome!
See you in my next... Take care!