Comparing 6 Frameworks for Rule-based PDF parsing

Motivation
Parsing PDFs is a fundamental step to gett started with fine-tuning an LLM or developing a Retrieval Augmented Generation (RAG) pipeline. People interested in language models are mostly interested in extracting text, numbers, and/or text from tables and at times even images such as figures, graphs, etc., which are quite common occurrences in PDFs. Without extracting this data, neither fine-tuning nor developing a RAG pipeline is possible.
Note: If you wish to get an overview of RAG, please check out this article.
Rule-based Parsing
Rule-based parsing, also referred to as template-based defines rules to extract information from PDF documents. A good example where rule-based parsing works is form filling. For example, an organization can use a standard template to enroll new employees. Rule-based parsing will work a charm for this example. Another good example could be extracting data from invoices and updating expenses into an in-house database.
Rule-based Parsing Frameworks
- PyPDF2. PyPDF2 is a pure Python library for reading and writing PDFs. It's good for simple text extraction and basic manipulation. Its simplicity also means that its support for complex layouts or images is limited.
- pdfminer. pdfminer specializes in text extraction from PDFs. It provides detailed layout analysis and it also supports various text encodings.
- PDFQuery. PDFQuery is built on top of pdfminer. It allows for more complex querying of PDF content. Moreover, it uses CSS-like selectors for targeting specific elements in a given PDF document.
- Camelot. Camelot specializes in extracting tables from PDFs. It offers both stream and lattice parsing methods. It is good for structured data extraction.
- PDFPluber. PDFPlumber is built on top of pdfminer.six (a fork of pdfminer). It provides detailed layout analysis and text extraction. It also includes tools for extracting tables and images.
- Tabula-py. Tabula is a Java library. So Tabula-py is not quite a Python library but rather a Python wrapper for Tabula-java. As the name suggests, it focuses on extracting tables from PDFs. As it's a specialized library for tabular format, it handles complex tables quite well in PDFs.
Hands-On
Without further adieu, let’s get our hands dirty with the frameworks. All the code for this article is available in this notebook.
In these examples, try to extract text, tables, and figures from the RAG paper published here. You may download and try it out yourself. Research papers are good candidates as almost all of them tend to have text, figures to explain the method, and some plots and tables to show the results.
PyPDF2
Installing PyPDF2 is very simple with pip. The specialty of PyPDF2 lies in its simplicity. So, simple text extraction goes like this:
import PyPDF2
# Reading text from a PDF
def read_pdf(file_path):
with open(file_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page in reader.pages:
text += page.extract_text() + "\n"
return text
Invoking the function,
text = read_pdf('rag_paper.pdf')
print(text)
Here are some parts of the results of text extraction.
issues because knowledge can be directly revised and expanded, and accessed knowledge can be
inspected and interpreted. REALM [ 20] and ORQA [ 31], two recently introduced models that
combine masked language models [ 8] with a differentiable retriever, have shown promising results,arXiv:2005.11401v4 [cs.CL] 12 Apr 2021
The Divine
Comedy (x) qQuery
Encoder
q(x)
MIPS p θGenerator pθ
We can notice that:
- It doesn’t care about equations. It just extracts them as text
- It doesn’t care about figures either. As the words, “The Divine Comedy (x) qQuery” are taken from Figure 1. in the paper.
Clearly, PyPDF2 is quite basic. The good news is that PyPDF2 is integrated with LangChain and LlamaIndex. For example, if you do from langchain_community.document_loaders import PyPDFLoader and load a PDF, it uses PyPDF2 behind the scenes.
pdfminer
We can get started with installing the framework. Note the difference in name for installation.
pip install pdfminer.six
We then need to import a few functions including the extract_text function which readily extracts the text from our PDF. Note that theextract_text is function readily available making it just a 1 line code to extract text with pdfminer!
from pdfminer.high_level import extract_text
from pdfminer.layout import LAParams
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from pdfminer.converter import TextConverter, PDFPageAggregator
from io import StringIO
# Simple text extraction
def extract_text_from_pdf(pdf_path):
return extract_text(pdf_path)
We can go one step further if our PDF has too many pages and extract a single page by providing the start_page and end_page parameters.
def extract_text_from_pages(pdf_path, start_page, end_page):
text = ""
with open(pdf_path, 'rb') as file:
manager = PDFResourceManager()
output = StringIO()
converter = TextConverter(manager, output, laparams=LAParams())
interpreter = PDFPageInterpreter(manager, converter)
for page in PDFPage.get_pages(file, page_numbers=range(start_page-1, end_page)):
interpreter.process_page(page)
text = output.getvalue()
converter.close()
output.close()
In addition, it has the potential to get more granular and extract text from specific areas of the PDF specified by providing the x1, y1, x2, y2 coordinates. This perfectly suits reading forms that follow a strict template. Below are some excerpts from the results that led me to by following observation:
There are several advantages to generating answers even when it is possible to extract them. Docu-
ments with clues about the answer but do not contain the answer verbatim can still contribute towards
a correct answer being generated, which is not possible with standard extractive approaches, leading
5
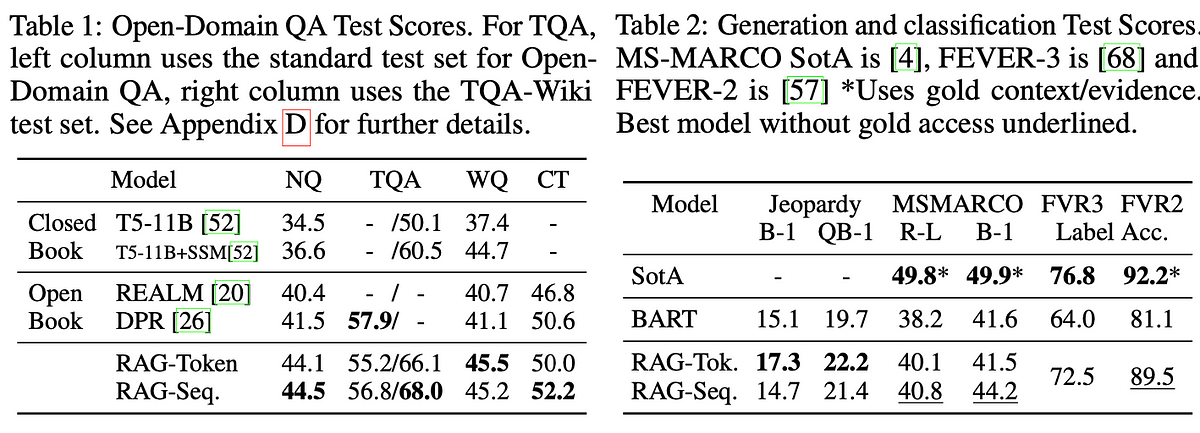
Table 1: Open-Domain QA Test Scores. For TQA,
left column uses the standard test set for Open-
Domain QA, right column uses the TQA-Wikiissues because knowledge can be directly revised and expanded, and accessed knowledge can be
inspected and interpreted. REALM [20] and ORQA [31], two recently introduced models that
combine masked language models [8] with a differentiable retriever, have shown promising results,
Figure 1: Overview of our approach. We combine a pre-trained retriever (Query Encoder + Document
Index) with a pre-trained seq2seq model (Generator) and fine-tune end-to-end. For query x, we use
Maximum Inner Product Search (MIPS) to find the top-K documents zi. For final prediction y, we
treat z as a latent variable and marginalize over seq2seq predictions given different documents.
- The framework seems to preserve the format of the input file
- It completely and safely ignores figures. This is better than extracting a jumble of text from figures and making life harder with further processing
- It safely ignores the tables but extracts the subtitles given to the tables.
Camelot
As we can notice from the shortcomings of pdfminer, tables are a different breed and hence need to be treated separately. This is where Camelot comes in. Recently Camelot has been renamed to pypdf_table_extractionas shown on the PyPi page below, making its usage explicit. But to work with it, we still need to import camelot. So I believe the underlying code hasn’t changed much.
So, let's give Camelot a spin to see how well it fares with tables. We need some dependencies like opencv and Ghostscript to process and visualize tables. So, installation becomes,
# install the library
!pip install camelot-py
# OpenCV is needed for camelot to work
!pip install opencv-python
# follow steps to install ghostscript from brew and then do the below step:
!pip install Ghostscript
!pip install matplotlib
Once it's installed, reading tables is just 1 line of code. But, unfortunately it did NOT extract a single table from the RAG paper. So I commented it out and tried to extract the tables from the example pdf file they have given in their website.
import camelot
import ghostscript
# Example 1: Basic table extraction
def extract_tables(pdf_path, pages=None):
if pages:
tables = camelot.read_pdf(pdf_path, pages=pages)
else:
tables = camelot.read_pdf(pdf_path)
return tables
tables = extract_tables('tables_example.pdf')
# tables = extract_tables('RAG.pdf')
print(f"Total tables extracted: {len(tables)}")
if len(tables):
print(tables[0].df)
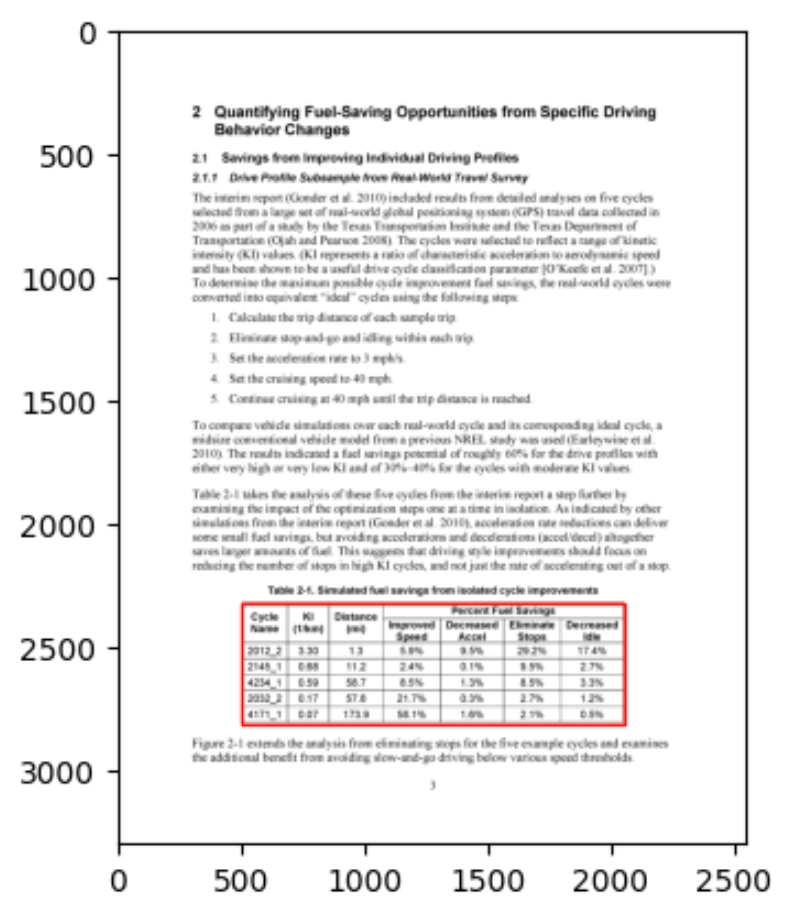
It worked a charm for their example and gave the result as below:
Total tables extracted: 1
0 1 2 3 \
0 Cycle \nName KI \n(1/km) Distance \n(mi) Percent Fuel Savings
1 Improved \nSpeed
2 2012_2 3.30 1.3 5.9%
3 2145_1 0.68 11.2 2.4%
4 4234_1 0.59 58.7 8.5%
5 2032_2 0.17 57.8 21.7%
6 4171_1 0.07 173.9 58.1%
4 5 6
0
1 Decreased \nAccel Eliminate \nStops Decreased \nIdle
2 9.5% 29.2% 17.4%
3 0.1% 9.5% 2.7%
4 1.3% 8.5% 3.3%
5 0.3% 2.7% 1.2%
6 1.6% 2.1% 0.5%
I also managed to plot the table it extracted using matplotlib as below:
I attribute the success to the well-defined borders (with lines) for tables. Academic papers don’t draw lines around tables and the sizes and format vary quite a lot, adding to the complexity. An example from the RAG paper is shown below. I am not surprised it proved challenging.
PDFPlumber
PDFplumber is a framework built on top of pdfminer. So am not surprised that the results resemble that of pdfminer. Even with pdfplumber, it's just 2 lines of code to extract tables as below,
!pip install pdfplumber
import pdfplumber
# pdf = pdfplumber.open("RAG.pdf")p
pdf = pdfplumber.open("tables_example.pdf")
table=pdf.pages[0].extract_table()
pd.DataFrame(table[1::],columns=table[0])
Sadly, the results were the same. I could even do a nice plot of the extracted table using Pandas data frame:
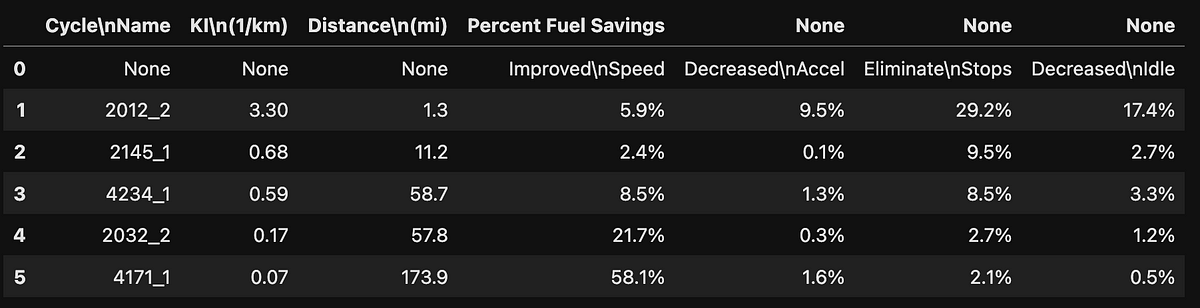
It managed to extract this table from the sample pdf file that we used with Camelot. However, I couldn’t get any tables extracted from the RAG paper. So, the hunt for the best table extractor continues.
tabula-py
Tabula is a Java framework for table extraction. Tabula-py is the Python wrapper around it. For it to work on any machine, we do need to Java Virtual Machine on it. Installing JVM is a breeze these days. I managed to download the dmg from the official page here
Once Java is sorted, installing tabula-py is just one line:
!pip install tabula-pyimport tabula
tables = tabula.read_pdf('RAG.pdf', pages='all')
# Print the number of tables extracted
print(f"Number of tables extracted: {len(tables)}")
print(tables[-2])
With the above code, it extracted 21 tables! But there aren’t 21 tables in the RAG paper. So it is overdoing its job and extracting even some text as tables. As an example, it managed to perfectly extract the table from the last page of the paper as below:
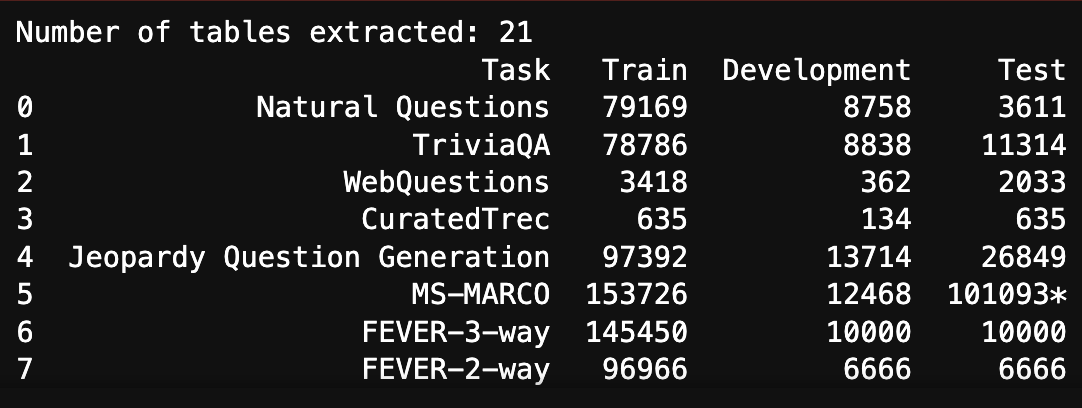
However, note that I am printing tables[-2] as it has extracted yet another table after extracting this last table in the paper!
Limitations
Honestly, all of the above frameworks are doing quite a competitive job. The biggest limitation of rule-based methods is that they serialize input PDF into one large sequence without preserving any structural elements such as tables as we saw before. This necessitates the need for more sophisticated methods.
In the upcoming articles, let’s dive into more sophisticated learning-based methods and compare the results with these simple rule-based methods.
Summary
Considering the results, I have summarized the pros and cons in the below table.
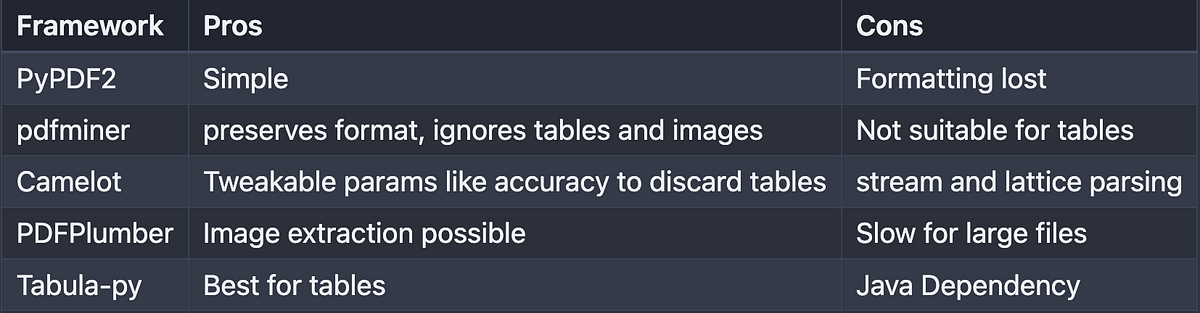
This article is the second in the series on PDF parsing which in itself is part of the broader series on Retrieval Augmented Generation (RAG). In the upcoming articles, we will dive deeper into another method with hands-on notebooks.
So please stay tuned!