Chunking in Retrieval Augmented Generation (RAG)

In my previous article, we saw a comprehensive overview of Retrieval Augmented Generation(RAG). We saw why we need RAG and in what situations the LLMs can overcome their limitations with the help of RAG.
As a quick refresher, this is what a simple pipeline with RAG looks like.
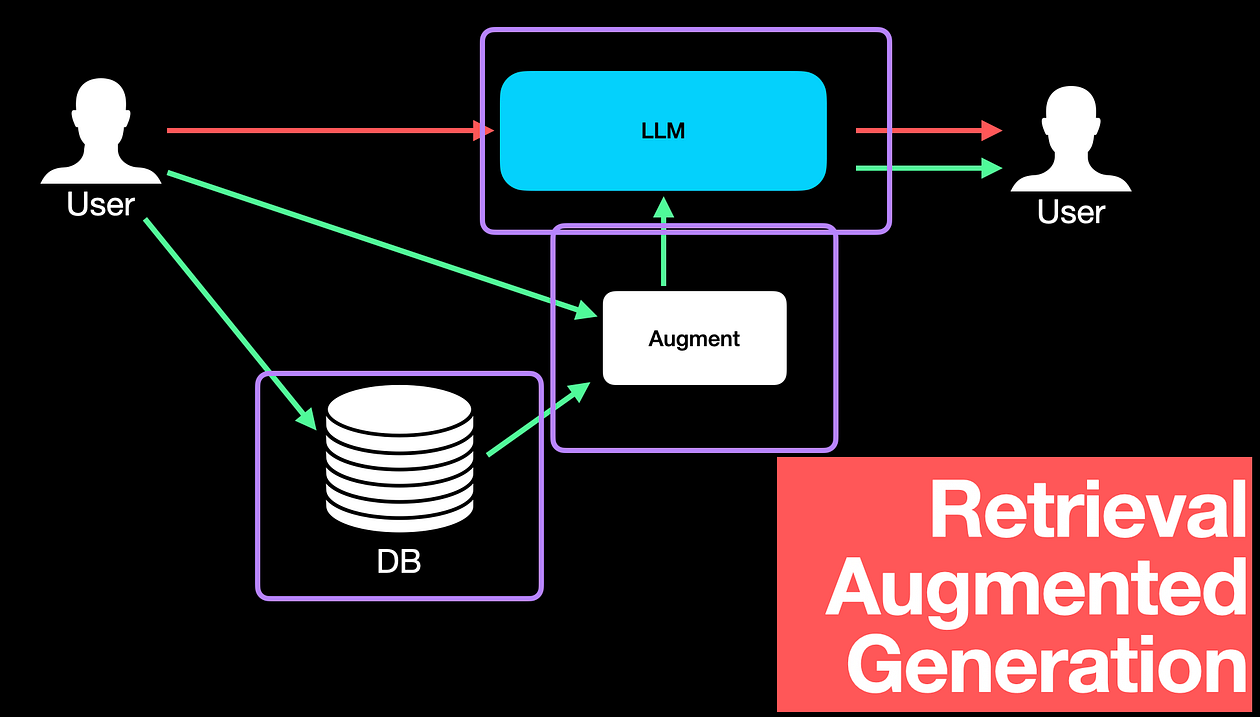
With RAG, we first create a vector DB of documents related to the domain. Whenever a user asks a question or prompts, we pass the prompt to the LLM and query our vector DB to retrieve related information. The retrieved information augments the prompt to provide more context to the LLM. The LLM is now context-aware and can answer the query better.
Whenever a user asks a question or prompts the LLM, it hits a vector DB. The DB is queried for relevant context. But how is this vector DB built? The steps involved in pre-processing data and creating the vector DB is called ingestion. It involves three steps namely, chunking, embedding, and indexing.
In this article, let's deep-dive into the first step which is chunking. Let's leave the others to the upcoming articles in this RAG series.
Video Explanation
If you would like to watch the video on this article, you may also head to YouTube explaining Chunking in RAG:
What is Chunking?
Text chunking is a technique in Natural Language Processing that divides input text into smaller segments. It can be based on the parts of speech, meanings of the words, etc. Chunking helps extract important information from text while ignoring the irrelevant ones.
Why Chunking?
The nature of NLP is that models deal with numbers. To convert text into numbers, we do an important operation called embedding, which we will deep-dive into in the coming weeks. Embedding is a crucial but essential operation for any LLM task. In our big data world where the data is ever-growing, we end up with a few problems:
- The scale of data. Embedding a huge document of say 10+ pages will only capture the gist of the story. The gist is the contextual information. Valuable information hidden in a few lines of the document gets lost very easily
- Model limitation. AI models only take in finite-sized inputs. Providing an entire book as input is impractical. So we need to break down inputs into chunks.
- Data management. Chunking can enable easy management of data. For example, instead of a single 30GB file, it will be much easier to divide it into 100 300MB files and keep them distributed.
- Retrieval efficiency. This is equivalent to how engineers approach any problem. When we break down the problem into smaller ones, it's much easier to solve it. Similarly, when data is broken down into smaller chunks, retrieval and information exchange becomes much easier.
- Improved accuracy. As we will see soon, dividing data into meaningful chunks helps the retrieval process to exactly retrieve the most relevant chunk of information. Thereby chunking improves the contextual information.
But how do we chunk inputs? Quite a few common methods are starting from simple fixed size to fancy agentic methods. Let's dive in.
Chunking Methods
Chunking and splitting are interchangeable terms. So for the sake of consistency, I am going to stick with chunking through this article.
Fixed-size chunking
This is the simplest of all. We define the length of the characters we need to include in a chunk. It can be implemented in 3 lines of code and it's much easier to see it in action than to explain in words. So,
text = "Better Three Hours Too Soon Than A Minute Too Late"
# list of chunks created
chunks = []
# define the num of characters in a chunk
chunk_size = 20
# split input
for i in range(0, len(text), chunk_size):
chunk = text[i:i + chunk_size]
chunks.append(chunk)
chunks
print(chunks)
['Better Three Hours T', 'oo Soon Than A Minut', 'e Too Late']
We could rather use LangChain’s CharacterSplitter to do the same. It gives us additional parameters like chunk_overlap and strip_whitespace options. So,
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size = 35,
chunk_overlap=0,
separator='',
strip_whitespace=False)
# documents is a datatype in LangChain
text_splitter.create_documents([text])
If we wish to do the same in LlamaIndex, then we have the option to do so.
from llama_index.text_splitter import SentenceSplitter
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["../../data/PGEssays/mit.txt"]
).load_data()
nodes = splitter.get_nodes_from_documents(documents)
Recursive chunking
We could do far better in the above example. For example, the first chunk, “Better Three Hours T” doesn’t make much sense at all. What if we split sentences based on say period or semicolon or “\n” token, etc? Or even any other symbols that we define? This gives rise to recursive chunking.
In recursive chunking, we provide a list of separators to use for splitting. The text is split using the first splitter. If the chunk size is big, the text is split using the second. This continues till all separators are used. Hence the name recursive.
Without taking the pain of implementing, let's make use of sophisticated frameworks. If we use LangChain, then we can do,
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size=100,
chunk_overlap=20,
separators=["\n\n", "\n"]
)
with open("state_of_the_union.txt") as f:
text = f.read()
splits = text_splitter.create_documents([text])
print(splits[0])
print(splits[1])
Using LlamaIndex, we should still use the recursive text splitter from LangChain but use LangchainNodeParse to parse documents and get the nodes object instead of the Documents object.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from llama_index.core.node_parser import LangchainNodeParser
parser = LangchainNodeParser(RecursiveCharacterTextSplitter(chunk_size=20, chunk_overlap=2))
documents = FlatReader().load_data(Path("state_of_the_union.txt"))
nodes = parser.get_nodes_from_documents(documents)
nodes[0]
Document chunking
Though the above method works a charm for text, in today’s multi-modal, big-data world, we have to deal with numerous document types like PDFs that have images, plots, tabular data, or even code snippets that need to be fed to code generation models. So to chunk such datatypes, we need a separate chunker for specific documents.
Let's say you wish to split Python documents, then we would probably split with different splitters and we will split the code using
from langchain.text_splitter import HTMLHeaderTextSplitter, \
MarkdownHeaderTextSplitter, \
LatexTextSplitter, \
PythonCodeTextSplitter
from langchain.text_splitter import Language
from langchain.text_splitter import PythonCodeTextSplitter
python_splitter = PythonCodeTextSplitter(chunk_size=100, chunk_overlap=0)
python_splitter.create_documents([python_text])
With LlamaIndex, lets say we are trying to split MarkDown instead of Python code. then,
from llama_index.core.node_parser import MarkdownNodeParser
from llama_index.readers.file import FlatReader
from pathlib import Path
md_docs = FlatReader().load_data(Path("README.md"))
let's
parser = MarkdownNodeParser()
md_nodes = parser.get_nodes_from_documents(md_docs)
print(md_nodes[0])
print(md_nodes[1])
As a sample, let's visualize a couple of nodes as shown below,
Node ID: eb3f7a6b-cf9c-4ef0-9445-8ba4d7a8031c
Text: 🗂️ LlamaIndex 🦙 [](https://pypi.org/project/llama-index/) [![GitHub contributors]
(https://img.shields.io/github/contributors/jerryjliu/llama_index)](ht
tps://github.com/jerryjliu/llama_index/graphs/contributors) [](https:/...
Node ID: 024412d4-ab32-4bf2-8d2e-fe48e76bdef7
Text: Important Links LlamaIndex.TS (Typescript/Javascript):
https://github.com/run-llama/LlamaIndexTS. Documentation:
https://docs.llamaindex.ai/en/stable/. Twitter:
https://twitter.com/llama_index. Discord:
https://discord.gg/dGcwcsnxhU.
Similarly, we can do so for any programming language such as JS, LaTeX, etc.
Semantic chunking
When we speak or write, our sentences always vary in length. And they must be meaningful. So in semantic chunking, we compare the meaning of two sentences to decide whether to chunk them or not. The first step towards extracting meaning from sentences is embedding them. So, we use an embedding model to embed two sentences. We then compute some similarity metrics to compare them. If they are above a threshold, they are chunked separately. Otherwise, they are together. In summary we,
- split into sentences
- then group into groups of 3 sentences
- merge one that are similar in the embedding space based on some chosen similarity metric.
In the below example, I have used the percentile as the threshold. It can be others like standard deviation, interquartile, gradient, etc.
For the embedding, we can either use OpenAI or if we wish to use opensource models, then we can use Ollama embeddings using the OllamaEmbeddings class from LangChain community.
# pip install langchain-experimental, langchain-openai
from langchain_experimental.text_splitter import SemanticChunker
# from langchain_openai.embeddings import OpenAIEmbeddings
from langchain_community.embeddings import OllamaEmbeddings
# chunker works by determining when to "break" apart sentences.
# This is done by looking for differences in embeddings between any two sentences.
# When that difference is past some threshold, then they are split.
# There are a few ways to determine what that threshold is,
# which are controlled by the breakpoint_threshold_type argument.
text_splitter = SemanticChunker(OllamaEmbeddings(model="nomic-embed-text"),
breakpoint_threshold_type="percentile")
with open("state_of_the_union.txt") as f:
text = f.read()
docs = text_splitter.create_documents([text])
print(docs[0])
Other methods
Dynamic Chunking
In the recursive method, we did not pay much attention to the chunk_size parameter. In other words, our chunks remained fixed. Do we humans not talk sentences of different lengths to convey messages? So would it not be wise to have chunks that are of different sizes too? This gives rise to dynamic chunking. We vary the chunk_size and chunk the given input.
We adjust the chunk sizes based on the length and structure of the input text. For example, we chunk based on clauses or sentence boundaries. We also look at each chunk and determine the character count. If the count exceeds a maximum character length, we chunk further. In no case can a chunk be less than a fixed-sized threshold.
Agentic Chunking
Agentic chunking is where an agent (running an LLM within) would reason about the input and chunk it cleverly. But I feel there is still time even in this fast-paced LLM era for anything agent-related to evolve and establish.
Choosing the right one
There are several considerations or factors that affect the chunking method chosen.
- Underlying Embedding model. Chunking is followed by embedding by an embedding model. So we need to choose chunking based on the underlying embedding model in use. Some models are trained with smaller chunks and so would work well with smaller chunks
- User’s query. Chunking can be dynamic based on the user’s query. If the user prompt is quite long, then we need to chunk it to retrieve the context for each of the chunks before feeding them to the LLM.
- Latency and performance. If we want real-time user experience as in a chat application, it's better to keep the pipeline lightweight with fewer chunks so that the response is quicker.
As a standard practice, people are choosing to use a chunk size of 1024 with chunk overlap. But this is bound to change as more methods emerge.
Conclusion
So to conclude, chunking is an essential process to ease our life with RAG. Chunking methods should be chosen wisely to improve the accuracy or any chosen metric of the RAG pipeline. Factors such as data management, retrieval efficiency and compute power available at our disposal should also be considered while choosing a chunking method. Frameworks such as LangChain and LlamaIndex have efficient implementations that will make chunking easy. Ambitious methods are fast evolving and are being implemented in these frameworks.